1-2 Основы, Назначение и функции ОС
В 1965-1975 гг. произошел переход от отдельных полупроводниковых
элементов к интегральным микросхемам, что открыло путь к появлению следующего
типа компьютеров. Большие функциональные возможности интегральных схем сделали
возможным осуществление на практике сложных компьютерных архитектур, таких,
например, как IBM/360. В это период были реализованы практически все основные
механизмы, присущие современным ОС: мультипрограммирование,
мультипроцессирование, поддержка многотерминального многопользовательского
режима, виртуальная память, файловые системы, разграничение доступа и сетевая
работа.. Революционным событием данного
этапа явилась промышленная реализация мультипрограммирования – способа
организации вычислительного процесса, при котором в памяти компьютера
находилось одновременно несколько попеременно выполняющихся программ. Такое
усовершенствование значительно улучшило эффективность вычислительной системы –
компьютер использовался теперь постоянно. В начале 70-х годов появились первые
сетевые ОС, которые в отличие от многотерминальных ОС позволяли не только
рассредоточить пользователей, но и организовать распределенное хранение и
обработку данных между несколькими компьютерами, связанными электрическими
сетями. К середине 70-х годов наряду с
мэйнфрэймами широкое распространение получили такие мини-компьютеры, как
PDP-11, NOVA, HP. Мини-компьютеры первыми использовали преимущества больших
интегральных схем, позволившие реализовать достаточно мощные функциональные
возможности при сравнительно невысокой стоимости.Важным событием в истории
мини-компьютеров и вообще в истории ОС явилось создание ОС UNIX. Первоначальна
она предназначалась для поддержания режима разделения времени в мини-компьютере
PDP-11. С середины 70-х годов началось массовое использование ОС UNIX. В 80-е
годы был разработан протокол2 TCP/IP, признанный в 1983
Министерством обороны США военным стандартом и реализованный для ОС BSD UNIX.
Все это десятилетие отмечалось постоянным появлением новых, все более
совершенных версий ОС UNIX. Среди них были и фирменные версии UNIX: SunOS,
HP-UX, Irix, AIX и многие другие, к которым производители компьютеров
адаптировали код ядра и системных утилит
для своей аппаратуры. Разнообразие версий породило проблему их совместимости,
периодически решаемую различными организациями. В результате этой работы
появились стандарты POSIX и XPG, определяющие интерфейсы ОС для приложений, а
специальное подразделение компании AT&T выпустило несколько версий UNIX
System III и UNIX System V, предназначенных для консолидации разработчиков на
уровне кода ядра. Начало 80-х годов также ознаменовалось важным событием в
истории ОС – появились персональные компьютеры. Они стали широко использоваться
неспециалистами, что потребовало разработки так называемого дружественного
программного обеспечения. Предоставление этих дружественных функций стало,
естественно, прямой обязанностью ОС. Первая версия наиболее популярной ОС
раннего этапа развития персональных компьютеров – MS-DOS компании Microsoft –
была лишена этих функциональных возможностей. В 1987 году в результате
совместных усилий Microsoft и IBM появилась на свет первая многозадачная ОС для
персональных компьютеров OS/2 с процессором Intel 80286, в полной мере
использующая возможности защищенного режима. В 90-е годы практически все ОС,
занимающие заметное место на рынке, стали сетевыми. Сетевые функции сегодня
являются неотъемлемой частью ОС и встраиваются в ее ядро. ОС получили средства
для работы со всеми основными технологиями локальных (Ethernet, Fast Ethernet,
Gigabit Ethernet, Token Ring, FDDI, ATM) и глобальных (X.25, frame relay, ISDN,
ATM) сетей, а также средства для создания составных сетей (IP, IPX, AppleTalk,
RIP, OSPF, NLSP
Во второй половине 90-х годов все компании-производители ОС резко
усилили поддержку своими системами средств работы с Интернетом. Кроме самого
стека протоколов TCP/IP, в комплект поставки начали включать утилиты,
реализующие такие популярные сервисы, как telnet, ftp, DNS и Web.
Рассмотрев краткую историю развития операционных систем, мы можем более
подробно остановиться на обсуждении выполняемых
ими функций.
Операционная система (ОС) компьютера представляет собой комплекс программ, организующих
вычислительный процесс в вычислительной системе.
ОС выполняет две группы функций:
1) предоставление пользователю вместо реальной
аппаратуры компьютера некой расширенной машины, с которой удобнее работать и
которую легче программировать;
2) повышение эффективности использования компьютера
путем рационального управления его ресурсами в соответствии с некоторым
критерием.
ОС не только предоставляет пользователям и программистам удобный
интерфейс к аппаратным средствам компьютера, но и является механизмом,
распределяющим ресурсы компьютера. К ресурсам вычислительной системы
относят такие ее средства, которые могут быть выделены процессу обработки
данных.
Ресурсы вычислительной системы можно разбить на первичные –
аппаратные ресурсы и вторичные – логические, программные и
информационные ресурсы.
К числу первичных ресурсов современных вычислительных систем относятся
процессоры, основная память, диски и др., за которыми стоят реальные аппаратные
средства. Они являются наиболее значимыми для вычислительного процесса.
Вторичные ресурсы связаны с техническими устройствами косвенно, так как
являются логическими, виртуальными. Однако их введение – это необходимая
абстракция, удобная не только для создателей ОС, но и для пользователей.
Управление ресурсами включает решение
следующих общих, не зависящих от типа ресурса задач:
1) планирование ресурса – определение, какому
процессу, когда и в каком количестве (если ресурс может быть разбит на части)
следует выделить данный ресурс;
2) удовлетворение запросов на ресурсы;
3) отслеживание состояния и учет использования
ресурса – поддержание оперативной информации о занятости ресурса и
распределенной его доли;
4) разрешение конфликтов между процессами,
использующими один ресурс.
Разработка и реализация алгоритмов управления ресурсами является очень
важным этапом при проектировании системы.
Функции ОС обычно группируются либо в соответствии с типами локальных
ресурсов, которыми управляет ОС, либо в соответствии со специфическими
задачами, применимыми ко всем ресурсам вычислительной системы. Такие группы
именуются подсистемами. Наиболее важные – это подсистемы управления
процессами, памятью, файлами и внешними устройствами, а подсистемами, общими
для всех ресурсов, являются подсистемы пользовательского интерфейса, защиты
данных и администрирования. Рассмотрим возложенные на них основные задачи.
Подсистема управления процессами генерирует системные информационные структуры,
содержащие данные о потребностях в ресурсах вычислительной системы, а также о
фактически выделенных ресурсах для каждой задачи. Процесс (задача) – представляет собой базовое понятие
современных ОС и часто кратко определяется как программа в стадии выполнения.
Программа – это статический объект, представляющий собой файл с кодами и
данными, процесс является динамическим объектом, который возникает в
операционной системе после того, как пользователь или ОС решает запустить
программу на выполнение. Во многих современных ОС для обозначения минимальной
единицы работы ОС используют термин “нить”, или “поток”, при этом изменяется
суть термина “процесс”.
В мультипрограммной ОС одновременно может существовать несколько
процессов, часть из которых, называемая пользовательскими процессами,
порождается по инициативе пользователей. Другие процессы инициализируются самой
ОС для выполнения своих функций и называются
системными.
Поскольку процессы довольно часто одновременно претендуют на одни и те
же ресурсы вычислительной системы, на ОС ложится задача поддержания очередей
заявок на такие ресурсы.
ОС берет на себя также функции синхронизации процессов, позволяющие
процессу приостанавливать свое выполнение до наступления какого-либо события в
системе, которым может быть, например, завершение операции ввода-вывода,
осуществляемой ОС по его запросу.
На подсистему управления памятью возложены очень важные функции, поскольку процесс
может выполняться только в том случае, если его коды и данные находятся в
оперативной памяти компьютера. Управление памятью включает в себя распределение
имеющейся в вычислительной системе физической памяти между всеми существующими
в данный момент в системе процессами, загрузку кодов и данных процессов в
отведенные им области памяти, настройку адресно-зависимых частей кодов процесса
на физические адреса выделенной области, а также защиту областей памяти каждого
процесса. Одним из наиболее популярных способов управления памятью в
современных ОС является так называемая виртуальная память. Наличие в ОС
механизма виртуальной памяти позволяет программисту писать программу так, как
будто в его распоряжении имеется однородная оперативная память большого объема,
часто существеннопревышающего объем имеющейся физической памяти.
Защита памяти
– это избирательная способность предохранять выполняемую задачу от операций
записи или чтения памяти, назначенной другой задаче. Правильно написанные
программы не делают некорректных попыток обратиться к памяти, используемой
другими программами. Однако вследствие того, что в реальных программах часто
содержатся ошибки, такие попытки могут предприниматься. Средства защиты памяти,
реализованные в ОС, должны пресекать несанкционированный доступ процессов к
чужим областям памяти.
Способность ОС к “экранированию” сложностей реальной аппаратуры ярко
проявляется в одной из основных подсистем ОС – файловой системе. ОС
виртуализирует отдельный набор данных, хранящихся на внешнем накопителе, в виде
файла – простой неструктурированной последовательности байтов, имеющей
символьное имя. Для удобства работы с данными файлы группируются в каталоги,
которые, в свою очередь, образуют группы – каталоги более высокого
уровня. Пользователь, применяя средства ОС, может выполнять над файлами и
каталогами такие действия, как поиск по имени, удаление, вывод содержимого на
внешнее устройство, изменение и сохранение содержимого
Подсистема управления внешними устройствами, называемая также подсистемой ввода-вывода,
является интерфейсом ко всем устройствам, подключенным к компьютеру. Множество
этих устройств очень велико. Номенклатура выпускаемых накопителей на жестких,
гибких и оптических дисках принтеров, сканеров, мониторов, плоттеров, модемов,
сетевых адаптеров и специализированных устройств ввода-вывода (например,
аналого-цифровых преобразователей, устройств считывания шрих-кода и т.д.)
насчитывает тысячи моделей. Эти модели отличаются набором и последовательностью
команд, используемых для обмена информацией с процессором и памятью компьютера,
скоростью работы, кодировкой передаваемых данных, возможностью совместного
использования, поддерживаемыми функциональными возможностями и множеством
других деталей. Программа, управляющая конкретной моделью внешнего устройства и
учитывающая все его особенности, называется драйвером этого устройства
(от англ. drive – управлять). Драйвер может управлять единственной моделью
устройства или же группой устройств определенного типа. Для конечного
пользователя важное значение имеет наличие в ОС как можно большего количества
разнообразных драйверов (для широкого спектра устройств), поскольку это
гарантирует возможность подключения к компьютеру большого числа внешних
устройств различных производителей. От наличия подходящих драйверов во многом
зависит успех ОС на рынке. Так, отсутствие многих необходимых драйверов внешних
устройств было одной из причин низкой популярности ОС OS/2 и ранних версий
Windows NT. Поэтому, прежде чем выпускать на рынок новую ОС, разработчики
стараются включить в ее состав драйверы для поддержки самого разного имеющегося
в продаже оборудования. Созданием драйверов занимаются как разработчики
конкретной ОС, так и специалисты компаний, выпускающих внешние устройства. ОС
должна поддерживать четко определенный
интерфейс между драйверами и остальными частями ОС, чтобы разработчики из
компаний-производителей устройств ввода-вывода могли поставлять вместе со
своими устройствами драйверы для данной ОС.
3-4
Классификация ОС
Рассмотрев назначение ОС и выполняемые ими функции, мы можем
классифицировать все многообразие существующих ОС, взяв за основу наиболее
общие классификационные принципы.
1) По количеству
одновременно существующих программных процессов ОС делятся на однопрограммные
и мультипрограммные. В мультипрограммных ОС, в отличие от
однопрограммных, вычислительный процесс
организуется таким образом, что в памяти компьютера находится одновременно
несколько программ, попеременно выполняющихся на одном процессоре. Такая организация
позволяет значительно повысить эффективность вычислительной системы.
2) По числу пользователей,
осуществляющих доступ к вычислительной системе, различают однопользовательские
и многопользовательские ОС. Многопользовательские системы предоставляют
возможность одновременного доступа к вычислительной системе нескольким
пользователям. При этом каждый из них работает за собственным терминалом,
однако все вычисления производятся на одном компьютере. Это приводит к более
эффективному использованию вычислительной техники и уменьшению стоимости
обработки данных.
3) По назначению
ОС делятся на универсальные и специализированные.
Специализированные ОС, как правило, работают с фиксированным набором программ.
Применение таких систем обусловлено невозможностью использования универсальной
ОС по соображениям эффективности, а также вследствие специфики решаемых задач.
4) По способу загрузки
можно выделить загружаемые ОС и системы, постоянно находящиеся в
памяти вычислительной системы. Последние, как правило, используются для
управления работой специализированных
устройств.
5) По особенности области использования ОС
подразделяются на системы пакетной обработки, системы разделения
времени и системы реального времени. Системы пакетной обработки
предназначаются в основном для решения задач вычислительного характера, не
требующих быстрого получения результатов. Критерием эффективности таких систем
является максимальная пропускная способность, то есть решение максимального
числа задач в единицу времени. Взаимодействие пользователя с вычислительной
системой сводится к тому, что он приносит задание, отдает его оператору, а
через некоторое время, после выполнения пакета заданий, получает результат.
Требования к ОС
Сегодня к ОС предъявляется множество требований. Главными из них,
конечно же, являются выполнение функций эффективного управления ресурсами
вычислительной системы и обеспечение удобного интерфейса для пользователя и
прикладных программ. Кроме того, можно выделить ряд основных требований,
которым должна удовлетворять любая современная ОС.
1) Производительность. ОС должна обладать настолько хорошим быстродействием
и временем реакции, насколько это позволяет аппаратная платформа. На
производительность ОС оказывает влияние множество факторов, среди которых
основными являются архитектура ОС, многообразие реализуемых ею функций,
количество ресурсов, потребляемых самой ОС для выполнения поставленных перед
ней задач, качество программного кода.
2) Надежность.
Это требование ОС определяется архитектурными решениями, положенными в ее основу, а также качеством реализации,
обратно пропорциональным количеству ошибок в комплексе программ, составляющих
ОС.
3) Защищенность.
Система должна быть защищена как от внутренних, так и от внешних ошибок, сбоев
и отказов. Ее действия должны быть всегда предсказуемы, а приложения не должны
иметь возможности наносить вред. Современная ОС защищает данные и другие
ресурсы вычислительной системы от несанкционированного доступа и от попыток
непреднамеренного повреждения этих данных.
4) Расширяемость. ОС является расширяемой, если в нее можно вносить дополнения и
изменения, не нарушая целостности системы. Расширяемость достигается за счет
модульной структуры ОС, при которой программы строятся из отдельных модулей,
взаимодействующих только через функциональный интерфейс. Такая архитектура
позволяет в случае необходимости добавлять новые или удалять ненужные
компоненты. Однако простота, с которой пользователь или системный программист
сможет производить такие функциональные изменения, определяется совершенством и
продуманностью применяемых при построении системы решений.
5) Переносимость. В идеальном случае ОС должна легко переноситься с одного типа
аппаратной платформы на другой. Реально это далеко не всегда быстро и легко выполнимая задача. Как правило, ОС
разрабатывается для определенного типа аппаратных платформ и перенос ее на
платформу с принципиально иным строением может стать трудной задачей.
6) Совместимость. ОС всегда изменяются со временем, и эти изменения более значимы, чем
изменения аппаратных средств. Изменения ОС обычно заключаются в приобретении
ими новых свойств, добавлении новых и модификации имеющихся функций. Под
требованием совместимости понимается сохранение возможности использования
прикладных программ, написанных для “старой” или вообще другой ОС, в новой ОС.
7) Удобство.
Средства ОС должны быть простыми и гибкими, а логика ее работы ясна пользователю. Современные ОС
ориентированы на обеспечение пользователю максимально возможного удобства при
работе с ними. Необходимым условием этого стало наличие у ОС графического
пользовательского интерфейса и всевозможных мастеров – программ,
автоматизирующих установку, настройку и эксплуатацию системы.
В зависимости от области
применения конкретной ОС изменяется и состав предъявляемых к ней требований.
5-6 Архитектура операционных
систем
Ядро и вспомогательные
модули ОС
Функциональная сложность
ОС неизбежно приводит к сложности ее архитектуры, под которой понимают
структурную организацию ОС на основе различных программных модулей.
Наиболее общим подходом
к структуризации ОС является разделение всех её модулей на две группы:
1) ядро – модули,
выполняющие основные функции ОС;
2) модули ОС, выполняющие вспомогательные функции ОС.
Модули ядра выполняют
такие базовые функции, как управление процессами, памятью, устройствами
ввода-вывода и т.д. Ядро составляет самую главную часть ОС, без которой она
является полностью неработоспособной и не может выполнять ни одну из своих
функций. В ядре решаются внутрисистемные задачи организации вычислительного
процесса, недоступные для приложений. Особый класс функций ядра служит для
поддержки приложений, создавая для них так называемую прикладную программную
среду. Приложения могут обращаться к ядру с запросами – системным вызовами
для выполнения тех или иных действий, например для открытия и чтения файла,
вывода графической информации на дисплей, получения системного времени и т.д.
Функции ядра, которые могут вызываться приложениями, образуют интерфейс
прикладного программирования – API (Application Programming Interface).
Для обеспечения высокой
скорости работы ОС все модули ядра или большая их часть постоянно находятся в
оперативной памяти, то есть являются резидентными модулями ОС.
Вследствие ограниченности такого ресурса системы, как оперативная память,
важное значение имеет размер этих постоянно размещенных в памяти модулей. Ядро
– это основной элемент всех вычислительных процессов в системе, поэтому крах
ядра приводит к краху всей вычислительной системы. Следовательно, разработчики
ОС должны уделять надежности кодов ядра особое внимание, даже если при этом
процесс их написания и отладки занимает очень длительное время. Как правило,
ядро ОС оформляется в виде программного модуля специального формата, отличного
от формата обычных пользовательских приложений.
Вспомогательные модули ОС выполняют не столь важные, как ядро,
функции. Например, это могут быть программы архивирования данных, редактирования текстов и многое другое.
Вспомогательные функции ОС, как правило, оформляются либо в виде
пользовательских приложений, либо в виде библиотек процедур и функций.
Вследствие того, что часть компонентов ОС разрабатывается в виде обычных
приложений, имеющих стандартный для данной ОС формат, то зачастую очень сложно
отделить вспомогательные модули ОС от обычных пользовательских приложений Вспомогательные
модули ОС, в свою очередь, делятся на следующие основные группы:
1) утилиты –
программы, решающие отдельные задачи управления и сопровождения вычислительной
системы, например программы архивации данных, сжатия дисков, тестирования
дисков;
2) системные обрабатывающие программы – текстовые или графические редакторы, компиляторы,
компоновщики, отладчики и другие программы, входящие в комплект поставки данной
ОС;
3) программы предоставления пользователю
дополнительных услуг – нестандартный
вариант пользовательского интерфейса, включающий вспомогательные и даже игровые
программы;
4) библиотеки процедур и функций различного назначения, облегчающие разработку
пользовательских приложений, например библиотека математических функций,
функций работы с устройствами ввода-вывода и т.д.
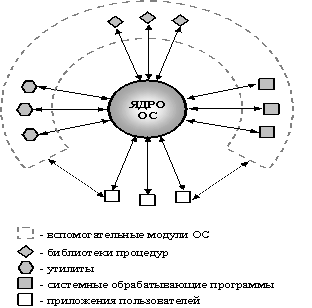 Как и обычные пользовательские приложения, все
перечисленные группы вспомогательных модулей при выполнении своих задач
обращаются к функциям ядра ОС. Схема взаимодействия ядра, вспомогательных
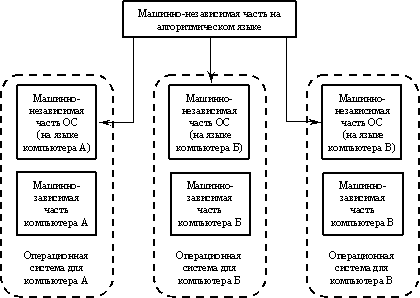
модулей ОС и пользовательских приложений приведена на рисунке 1.
Как и обычные пользовательские приложения, все
перечисленные группы вспомогательных модулей при выполнении своих задач
обращаются к функциям ядра ОС. Схема взаимодействия ядра, вспомогательных
модулей ОС и пользовательских приложений приведена на рисунке 1.
За счет разделения ОС на ядро и вспомогательные модули обеспечивается
легкая расширяемость ОС. Действительно, для добавления новой высокоуровневой
функции достаточно разработать соответствующее приложение, при этом не
требуется модифицировать функции, составляющие ядро системы. С учетом того, что
вспомогательные модули системы, как правило, оформляются в виде стандартных
пользовательских приложений, их модификация или замена старых версий на более
новые производится достаточно просто и может быть выполнена даже обычным
пользователем с применением специальной системной утилиты – мастера обновлений.
Достаточно только получить от производителя ОС файлы с обновленными модулями,
запустить мастер обновления и указать ему расположение этих файлов. Гораздо
более сложным является внесение изменений в функции ядра. Произвести такие действия по силам только
квалифицированному специалисту, причем в
зависимости от структурной организации
ядра для этого может потребоваться даже полная его перекомпиляция.
Вспомогательные модули ОС обычно загружаются в оперативную память
вычислительной системы только на время выполнения своих функций, то есть
являются транзитными модулями ОС. Постоянно в оперативной памяти
находятся лишь наиболее важные программы ОС, составляющие ее ядро. Применение
подобной организации позволяет рационально использовать такой ресурс
вычислительной системы, как оперативная память.
Требование обеспечения надежности выполнения приложений приводит к
необходимости наличия у ОС некоторых привилегий. Необходимо предотвратить
возможность вмешательства в работу ОС или разрушения какой-либо ее части
вследствие выполнения некорректно работающих приложений. ОС должна обладать исключительными
правами по отношению к другим приложениям. В мультипрограммных системах это
просто необходимо для разрешения споров из-за ресурсов вычислительной системы
между приложениями.
Несомненно, что
обеспечение соответствующих привилегий ОС требует не только соответствующей
программной, но и аппаратной поддержки. Аппаратура компьютера должна иметь
возможность работать как минимум в двух
режимах – пользовательском режиме (user mode) и привилегированном режиме, который
также называется режимом ядра (kernel mode), или режимом супервизора
(supervisor mode). В пользовательском режиме работы запрещено выполнение
некоторых критичных для системы команд, связанных с переключением процессора
между задачами, управлением устройствами ввода-вывода, доступом к механизмам
распределения и защиты памяти. Некоторые команды в пользовательском режиме
запрещено выполнять безусловно (например, команду перехода к привилегированному
режиму работы), тогда как выполнение
других запрещено только при определенных условиях
 Как уже было сказано, в
ядре ОС осуществляются все основные функции. Вследствие этого именно ядро становится той частью ОС, которая
выполняется в привилегированном режиме, а пользовательские приложения,
соответственно, – в пользовательском режиме. Повышение устойчивости и
надежности ОС, обеспечиваемое за счет работы ядра в привилегированном режиме,
тем не менее приводит к замедлению выполнения приложений, поскольку для
переключения процессора из пользовательского режима в привилегированный и
обратно требуется некоторое, пусть и небольшое, время (рис. 2). Следовательно,
во всех типах процессоров из-за дополнительной двукратной задержки переключения
переход на процедуру со сменой режима выполняется медленнее, чем вызов
процедуры без смены режима.
Как уже было сказано, в
ядре ОС осуществляются все основные функции. Вследствие этого именно ядро становится той частью ОС, которая
выполняется в привилегированном режиме, а пользовательские приложения,
соответственно, – в пользовательском режиме. Повышение устойчивости и
надежности ОС, обеспечиваемое за счет работы ядра в привилегированном режиме,
тем не менее приводит к замедлению выполнения приложений, поскольку для
переключения процессора из пользовательского режима в привилегированный и
обратно требуется некоторое, пусть и небольшое, время (рис. 2). Следовательно,
во всех типах процессоров из-за дополнительной двукратной задержки переключения
переход на процедуру со сменой режима выполняется медленнее, чем вызов
процедуры без смены режима.
Описанная выше архитектура,
основанная на привилегированном ядре и приложениях пользовательского режима,
стала классической. Ее применяют многие популярные ОС, в том числе версии UNIX,
VAX VMS, IBM OS/390, OS/2.
«Классическая»
архитектура ОС
Многослойная структура ОС
Существует универсальный
и эффективный подход к построению сложной системы любого типа – многослойный
подход. В соответствии с ним система делится на иерархию слоев, каждый из
которых обслуживает вышележащий слой, выполняя для него некоторый набор
функций, образующих так называемый межслойный интерфейс. Основываясь на
функциях, предоставляемых нижележащим слоем, вышележащий слой строит свои более
мощные функции, являющиеся основой для создания функций еще более высокого в
иерархии слоя. Межслойные интерфейсы, с помощью которых происходит
взаимодействие слоев, строго оговорены,
тогда как связи между модулями внутри одного слоя могут быть произвольными.
 Если применить описанный подход к вычислительной
системе, работающей под управлением ОС, построенной по классической
архитектуре, то ее можно представить как систему, состоящую из трех
иерархически связанных слоев, каждый из которых взаимодействует только со
смежным ему слоем. При этом нижний слой составляет аппаратура, средний включает
в себя ядро, а самый верхний – утилиты, системные обрабатывающие программы и
приложения.
Если применить описанный подход к вычислительной
системе, работающей под управлением ОС, построенной по классической
архитектуре, то ее можно представить как систему, состоящую из трех
иерархически связанных слоев, каждый из которых взаимодействует только со
смежным ему слоем. При этом нижний слой составляет аппаратура, средний включает
в себя ядро, а самый верхний – утилиты, системные обрабатывающие программы и
приложения.
Однако не только система в целом, но и ядро ОС является сложным
многофункциональным комплексом программ, а значит к нему, в свою очередь, также
можно применить многослойный подход. Как правило, в ядре классической ОС
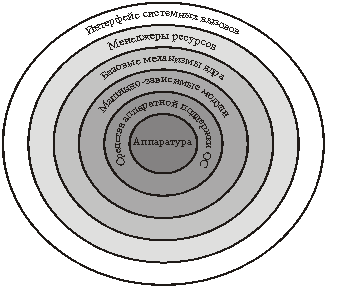
выделяют следующие основные слои (рис. 4):
- средства
аппаратной поддержки ОС, к
которым относятся аппаратные средства системы, напрямую участвующие в
вычислительном процессе: средства поддержки привилегированного режима и защиты
областей памяти, система прерываний и т.д. Их можно считать составляющей частью
ОС. Набор и функциональные возможности аппаратных средств могут меняться и
определяются разработчиком конкретной системы;
- машинно-зависимые компоненты ОС,
включающие в себя программные модули, отражающие специфику аппаратной платформы
компьютера. Теоретически именно этот слой должен делать вышележащие слои ядра
полностью независимыми от особенностей аппаратуры, что позволяет разрабатывать
машинно-независимые вышележащие слои и обеспечивать тем самым возможность
переносимости ОС;
- базовые
механизмы ядра, выполняющие
наиболее примитивные операции ядра, например контекстное переключение
процессов, перемещение участков памяти на диск и обратно и т.д. Модули данного
ядра не принимают решения о распределении ресурсов вычислительной системы, а
только отрабатывают принятые вышележащими слоями решения;
- менеджеры ресурсов, реализующие задачи по
стратегическому управлению основными ресурсами вычислительной системы. Слой
состоит из сложных и мощных функциональных модулей. Каждый менеджер ресурсов
(называемый также диспетчером) ведет учет свободных и используемых
ресурсов соответствующего типа и планирует их распределение в соответствии с
запросами приложений. Для управления ресурсами менеджеры ресурсов используют
функции нижележащего слоя – базовых механизмов ядра;
- интерфейс системных вызовов непосредственно
взаимодействует с приложениями и системными утилитами, образуя прикладной
программный интерфейс операционной системы (API). Является самым верхним слоем
в иерархи слоев ядра. Обслуживающие системные вызовы функции API предоставляют
доступ к ресурсам вычислительной системы в удобной и компактной форме без
указания деталей их физического расположения.
7
Микроядерная архитектура ОС
Основные положения микроядерной архитектуры
Микроядерная архитектура
является альтернативой рассмотренному выше классическому способу построения ОС.
В отличие от традиционной архитектуры, согласно которой ОС представляет собой
монолитное ядро, реализующее основные функции по управлению аппаратными
ресурсами и организующее среду для выполнения пользовательских процессов,
микроядерная архитектура распределяет функции ОС между микроядром и входящими в
состав ОС системными сервисами, реализованными в виде процессов, равноправных с
пользовательскими приложениями.
Рассмотрим концепцию
микроядерной архитектуры построения ОС. Главной особенностью данного подхода
является то, что в привилегированном режиме остается работать только очень
малая часть ОС, называемая соответственно микроядром. Микроядро защищено
от остальных частей ОС и пользовательских приложений. Набор входящих в состав
микроядра функций, как правило, соответствует слою базовых механизмов обычного
ядра, хотя в состав микроядра включаются далеко не все базовые функции ядра, а
только функции управления процессами, обработки прерываний, управления
виртуальной памятью, пересылки сообщений, управления устройствами ввода-вывода.
Выполнение таких функций ОС практически невозможно реализовать в
пользовательском режиме. Все машинно-зависимые модули ОС также включаются в
микроядро.
Не вошедшие в состав
микроядра высокоуровневые функции и модули ядра оформляются в виде обычных
приложений, работающих в пользовательском режиме. При этом на разработчика ОС
ложится далеко неоднозначная задача принятия решения о том, какой из
модулей будет работать в
привилегированном режиме, а какой в пользовательском. Как правило, на это
решение сильное влияние оказывает специфика применения данной ОС и критерии,
которым она должна удовлетворять. В общем случае многие менеджеры ресурсов,
являющиеся неотъемлемой частью ядра ОС с классической архитектурой, остаются за
пределами микроядра и работают в пользовательском режиме. На рисунке ниже
можно видеть основные различия в построении ОС с монолитным ядром (рис. 5а) и с
микроядерной архитектурой (рис. 5б).
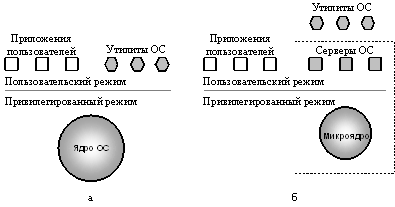 Работающие в
пользовательском режиме менеджеры ресурсов имеют принципиальные отличия от
традиционных утилит ОС и системных обрабатывающих программ ОС, хотя при
микроядерной архитектуре всеэти программные компоненты также оформлены в виде
приложений. Утилиты и обрабатывающие программы вызываются в основном
пользователями. Ситуации, когда одному приложению требуется выполнение функции
другого приложения, возникают крайне редко, поэтому в ОС с классической
архитектурой отсутствует механизм, с помощью которого одно приложение могло бы
вызвать функции другого. Принципиально другая ситуация возникает в том случае,
если в форме обычного приложения оформляется часть ОС. По определению основным
назначением такого приложения является обслуживание запросов других приложений,
например создание процесса, выделение памяти, проверка прав доступа к ресурсу и
т.д. Вследствие этого вынесенные в пользовательский режим менеджеры ресурсов
являются серверами ОС, то есть модулями, основное назначение которых –
обслуживание запросов локальных приложений и других модулей ОС. Совершенно
очевидно, что при реализации микроядерной архитектуры необходимо обеспечить
наличие в ОС удобного и эффективного способа вызова процедур одного процесса из
другого. Поддержка такого механизма является одной из главных задач,
возложенных на микроядро ОС.
Работающие в
пользовательском режиме менеджеры ресурсов имеют принципиальные отличия от
традиционных утилит ОС и системных обрабатывающих программ ОС, хотя при
микроядерной архитектуре всеэти программные компоненты также оформлены в виде
приложений. Утилиты и обрабатывающие программы вызываются в основном
пользователями. Ситуации, когда одному приложению требуется выполнение функции
другого приложения, возникают крайне редко, поэтому в ОС с классической
архитектурой отсутствует механизм, с помощью которого одно приложение могло бы
вызвать функции другого. Принципиально другая ситуация возникает в том случае,
если в форме обычного приложения оформляется часть ОС. По определению основным
назначением такого приложения является обслуживание запросов других приложений,
например создание процесса, выделение памяти, проверка прав доступа к ресурсу и
т.д. Вследствие этого вынесенные в пользовательский режим менеджеры ресурсов
являются серверами ОС, то есть модулями, основное назначение которых –
обслуживание запросов локальных приложений и других модулей ОС. Совершенно
очевидно, что при реализации микроядерной архитектуры необходимо обеспечить
наличие в ОС удобного и эффективного способа вызова процедур одного процесса из
другого. Поддержка такого механизма является одной из главных задач,
возложенных на микроядро ОС.
Рассмотрим типичный пример организации механизма обращения приложений к
функциям ОС, оформленным в виде серверов (рис. 6).
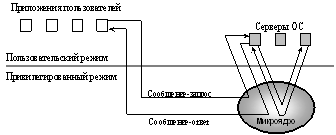 Клиент,
которым может быть как пользовательская прикладная программа, так и другой
компонент ОС, запрашивает у соответствующего сервера выполнение некоторой
функции, посылая ему сообщение. Микроядро ОС, выполняющееся в привилегированном
режиме, имеет доступ к адресным пространствам каждого из этих приложений и
поэтому может выступать в качестве посредника при передаче сообщений. Микроядро
сначала передает сообщение, содержащее имя и параметры вызываемой процедуры
соответствующему серверу, затем сервер выполняет запрошенную операцию, после
чего микроядро возвращает результаты клиенту посредством другого сообщения.
Таким образом, работа микроядерной ОС соответствует известной модели клиент-сервер,
в которой роль транспортных средств выполняет микроядро.
Клиент,
которым может быть как пользовательская прикладная программа, так и другой
компонент ОС, запрашивает у соответствующего сервера выполнение некоторой
функции, посылая ему сообщение. Микроядро ОС, выполняющееся в привилегированном
режиме, имеет доступ к адресным пространствам каждого из этих приложений и
поэтому может выступать в качестве посредника при передаче сообщений. Микроядро
сначала передает сообщение, содержащее имя и параметры вызываемой процедуры
соответствующему серверу, затем сервер выполняет запрошенную операцию, после
чего микроядро возвращает результаты клиенту посредством другого сообщения.
Таким образом, работа микроядерной ОС соответствует известной модели клиент-сервер,
в которой роль транспортных средств выполняет микроядро.
8 Аппаратная зависимость и
переносимость операционных систем
Аппаратно-зависимые
компоненты ОС
Как уже отмечалось
ранее, решение о том, какие функции ОС будут выполняться программно, а какие
аппаратно, принимается разработчиками ОС, поэтому не существует четкого
разделения между программной и аппаратной реализацией функций ОС. Несмотря на
это, практически все современные аппаратные платформы имеют некоторый типичный
набор средств аппаратной поддержки ОС, в который входят следующие компоненты:
Средства поддержки привилегированного режима обычно основаны на
системном регистре процессора, часто называемом “словом состояния”
машины или процессора. Этот регистр содержит некоторые признаки, определяющие
режимы работы процессора, в том числе и признак текущего режима привилегий.
Смена режима привилегий осуществляется за счёт изменения слова состояния машины
в результате прерывания или выполнения привилегированной команды. Число уровней
привилегий может быть разным у разных типов процессоров, однако, наиболее часто
используется либо два уровня (ядро–пользователь), либо четыре (например,
ядро–супервизор–выполнение–пользователь у платформы VAX, или 0–1–2–3 у
процессоров Intel x86/Pentium).
Средства трансляции адресов выполняют операции
преобразования виртуальных адресов, которые содержатся в кодах процесса, в
адресафизической памяти. Таблицы, предназначенные для трансляции адресов,
обычно имеют большой объем, поэтому они хранятся в оперативной памяти, а
аппаратура процессора использует только указатели на эти области. Средства
трансляции адресов применяют данные указатели для доступа к элементам таблиц и
аппаратного выполнения алгоритма преобразования адреса, что значительно
ускоряет процедуру трансляции по сравнению с ее чисто программной реализацией.
Средства переключения процессов предназначены
для быстрого сохранения контекста приостанавливаемого процесса и восстановления
контекста процесса, который становится активным. Контекст обычно включает
содержимое всех регистров общего назначения процессора, регистра флагов
операций (то есть флагов нуля, переноса, переполнения и т.п.), а также тех
системных регистров и указателей, которые связаны с отдельным процессом, а не
ОС, например указателя на таблицу трансляции адресов процесса. Для хранения
контекстов приостановленных процессов обычно используются области оперативной
памяти, которые поддерживаются указателями процессора.
Система прерываний позволяет
компьютеру реагировать на внешние события, синхронизировать выполнение
процессов и работу устройств ввода-вывода, быстро переходить с одной программы
на другую. Прерывание – это временное прекращение выполнения команд
программы с сохранением информации о ее текущем состоянии и передачей
управления специальной программе – обработчику прерываний.
Системный таймер, часто реализуемый в виде быстродействующего
регистра-счетчика, необходим ОС для выдержки интервалов времени. В регистр
таймера программно загружается значение требуемого интервала в условных
единицах, из которого затем автоматически с определенной частотой начинает
вычитаться по единице. Частота “тиков” таймера, как правило, тесно связана с
частотой тактового генератора процессора. Заметим, что не следует путать таймер
ни с тактовым генератором, вырабатывающем сигналы по синхронизации всех
операций в компьютере, ни с системными часами – работающей на батареях
электронной схеме, ведущие независимый отсчет времени и календарной даты.
средства защиты областей памяти обеспечивают
на аппаратном уровне проверку возможности программного кода осуществлять с
данными определенной области памяти такие операции, как чтение, запись или
выполнение (при передачах управления).
Если аппаратура компьютера поддерживает механизм трансляции адресов, то
средства защиты областей памяти встраиваются в этот механизм. Функции
аппаратуры по защите памяти обычно состоят в сравнении уровней привилегий
текущего кода процессора и сегмента памяти, к которому производится обращение.
Объем машинно-зависимых
компонентов ОС зависит от того, насколько велики отличия в аппаратных
платформах, для которых разрабатывается ОС. Например, ОС, построенная на
32-битовых адресах, для переноса на машину с 16-битовыми адресами должна быть
практически переписана заново. Одно из наиболее очевидных отличий – несовпадение
системы команд процессоров – преодолевается достаточно просто. Как правило,
современная ОС программируется на языке высокого уровня, а затем
соответствующим компилятором вырабатывается код для конкретного типа
процессора. Однако во многих случаях различия в организации аппаратуры
компьютера лежат гораздо глубже и преодолеть их таким образом не удается.
Например, однопроцессорный и двухпроцессорный компьютеры требуют применения в
ОС совершенно разных алгоритмов распределения процессорного времени. Аналогично,
отсутствие аппаратной поддержки виртуальной памяти приводит к принципиальному
различию в реализации подсистемы управления памятью. В таких случаях
разработчикам не удается обойтись без внесения в код ОС специфики аппаратной
платформы, для которой эта ОС предназначается.
Для уменьшения
количества машинно-зависимых модулей производители ОС обычно ограничивают
универсальность машинно-независимых модулей. Это означает, что их независимость
носит условный характер и распространяется только на несколько типов
процессоров и, естественно, созданных на основе этих процессоров аппаратных
платформ. По этому пути, например, пошли разработчики Windows NT, ограничив
количество типов процессоров, поддерживаемых ОС, четырьмя и поставляя различные
варианты кодов ядра для однопроцессорных и многопроцессорных компьютеров.
Для компьютеров,
построенных на основе процессоров Intel x86/Pentium, разработка экранирующего
машинно-зависимого слоя ОС значительно упрощается за счет наличия встроенной в
постоянную память компьютера базовой системы ввода-вывода – BIOS. BIOS
содержит драйверы для всех устройств, входящих в базовую конфигурацию
компьютера: жестких и гибких дисков, клавиатуры, дисплея и т.д. Эти драйверы
выполняют весьма примитивные операции с управляемыми устройствами, например
чтение группы секторов данных с определенной дорожки диска, но за счет этих
операций экранируются различия аппаратных платформ персональных компьютеров и
серверов на процессорах Intel разных производителей.
Таким образом, любая ОС
для решения своих задач взаимодействует с аппаратными средствами компьютера, а
именно: средствами поддержки привилегированного режима и трансляции адресов,
средствами переключения процессов и защиты областей памяти, системой прерываний
и системным таймером. Это делает ОС машинно-зависимой, привязанной к
определенной аппаратной платформе.
3.2. Переносимость ОС
Операционная система
называется переносимой ОС (portable), или мобильной, если ее код
может быть сравнительно легко перенесен с процессора одного типа на процессор
другого типа и с аппаратной платформы одного типа на аппаратную платформу
другого типа.
Несмотря на то что
зачастую ОС описываются либо как переносимые, либо как непереносимые,
мобильность – это не бинарное состояние, а понятие степени. Вопрос на самом деле
не только и не столько в том, может ли быть система перенесена, а в том,
насколько легко можно это сделать. Ведь если для переноса ОС с одного
компьютера на другой необходимо переписать заново практически все ее модули,
такая система не будет считаться переносимой, хотя принципиально ее можно
назвать и так. Для того чтобы обеспечить свойство мобильности ОС, разработчик
должен следовать установленным правилам.
1) Подавляющая часть
кода должна быть написана на языке, трансляторы которого имеются на всех машинах,
куда предполагается переносить систему. Такими языками, например, являются
стандартизированные языки высокого уровня. Большинство переносимых ОС написано
на языке C, который имеет много особенностей, полезных для разработки кодов ОС,
и компиляторы которого широко доступны. Языки низкого уровня не подходят для
решения подобных задач. Так, программа, написанная на ассемблере, является
переносимой только в том случае, когда перенос ОС предполагается на компьютер,
обладающий той же системой команд. В остальных случаях ассемблер используется
только для тех непереносимых частей ОС,
которые должны непосредственно взаимодействовать с аппаратурой (например, для
обработчика прерываний), или частей, требующих максимальной
производительности(например, для целочисленной арифметики повышенной точности).
2) Объем машинно-зависимых частей кода,
непосредственно взаимодействующих с аппаратными средствами, должен быть по
возможности минимизирован. Всегда следует избегать прямого манипулирования
регистрами и другими аппаратными средствами процессора. Для уменьшения
аппаратной зависимости разработчики ОС должны также исключить возможность
использования по умолчанию стандартных конфигураций аппаратуры или их
характеристик. Аппаратно-зависимые параметры можно “спрятать” в программно-задаваемые
пользователем данные абстрактного типа. Для осуществления всех необходимых
действий по управлению аппаратурой, представленной этими параметрами, должен
быть написан набор аппаратно-зависимых функций. Каждый раз, когда какому-либо
модулю ОС требуется выполнить некоторое действие, связанное с аппаратурой, он
манипулирует абстрактными данными, используя соответствующую функцию из
имеющегося набора. Когда ОС переносится, то соответственно изменяются только
эти данные и функции, которые ими манипулируют. Например, в ОС Windows NT
диспетчер прерываний преобразует аппаратные уровни прерываний конкретного типа
процессора в стандартный набор уровней прерываний IRQL, с которым работают
остальные модули ОС. Поэтому при переносе Windows NT на новую аппаратную
платформу необходимо переписать те коды диспетчера прерываний, которые, в
частности, занимаются отображением уровней прерывания на абстрактные уровни
IRQL, а модули ОС, пользующиеся этими абстрактными уровнями, изменений не
потребуют. Более того, в Windows NT любой ресурс системы, одновременно
задействованной более чем в одном процессе, включая файлы, совместно
используемую память и физические устройства, реализован в виде объекта и
управляется рядом функций. Такой подход сокращает число преобразований, которые
необходимо внести в ОС в процессе ее эксплуатации. Если, скажем, изменилось
что-то в аппаратуре, то все, что необходимо сделать, – это заменить
соответствующий объект. Аналогично, если требуется поддержка новых ресурсов, то
надо только добавить новый объект, не меняя при этом остального кода ОС.
Наиболее фундаментальное отличие между объектом и обыкновенной структурой
данных заключается в том, что внутренняя структура данных объекта скрыта от
наблюдения. Вы должны вызвать объектную функцию для того, чтобы получить данные
из объекта или поместить данные в объект. Вы не можете непосредственно изменять
данные, находящиеся внутри объекта. Это отделяет средства реализации объекта от
кода, который только использует его, такая техника позволяет легко изменять
впоследствии реализацию объектов.
 3) Аппаратно-зависимый код должен быть надежно
изолирован в нескольких модулях, а не быть распределен по системе. Изоляции
подлежат все части ОС, которые отражают специфику как процессора в отдельности,
так и используемой аппаратной платформы в целом. Низкоуровневые компоненты ОС,
имеющие доступ к процессорно-зависимым структурам данных и регистрам, должны
быть в обязательном порядке оформлены в виде компактных логически обособленных
модулей, которые могут быть заменены аналогичными по выполняемым функциям
модулями для других процессоров. Для снятия платформенной зависимости,
возникающей из-за различий между компьютерами разных производителей,
построенными на одном и том же процессоре, должен быть введен хорошо локализованный
программный слой машинно-зависимых функций с четко оговоренным межслойным
интерфейсом.
3) Аппаратно-зависимый код должен быть надежно
изолирован в нескольких модулях, а не быть распределен по системе. Изоляции
подлежат все части ОС, которые отражают специфику как процессора в отдельности,
так и используемой аппаратной платформы в целом. Низкоуровневые компоненты ОС,
имеющие доступ к процессорно-зависимым структурам данных и регистрам, должны
быть в обязательном порядке оформлены в виде компактных логически обособленных
модулей, которые могут быть заменены аналогичными по выполняемым функциям
модулями для других процессоров. Для снятия платформенной зависимости,
возникающей из-за различий между компьютерами разных производителей,
построенными на одном и том же процессоре, должен быть введен хорошо локализованный
программный слой машинно-зависимых функций с четко оговоренным межслойным
интерфейсом.
В идеальном случае слой
машинно-зависимых компонентов ядра полностью экранирует остальную часть ОС от
конкретных деталей аппаратной платформы или тех платформ, которые поддерживает
данная ОС. В результате таких действий происходит как бы подмена реальной
аппаратуры некой унифицированной расширенной машиной, одинаковой с точки зрения
пользователя для всех возможных вариантов аппаратной платформы. Все слои, лежащие
выше слоя машинно-зависимых компонентов, могут быть написаны для управления
именно этой виртуальной аппаратурой. Таким образом, у разработчиков появляется
возможность создавать один вариант машинно-независимой части ОС (включая
компоненты ядра, утилиты, системные обрабатывающие программы) для всего набора
поддерживаемых аппаратных платформ (рис. 8) .
10-11 Совместимость
операционных систем
Виды совместимости
Свойство ОС,
характеризующее возможность выполнения в ОС приложений, написанных для других
ОС, называется совместимостью.
Существует два
принципиально отличающихся вида совместимости, которые не следует путать: совместимость на двоичном уровне
и совместимость на уровне исходных текстов. Приложения обычно
хранятся в компьютере в виде исполняемых файлов, содержащих двоичные образы
кодов и данных.
Двоичная совместимость достигается в
том случае, если можно взять исполняемую программу, работающую в среде одной
ОС, и запустить ее на выполнение в среде другой ОС.
Совместимость на уровне исходных
текстов требует наличия соответствующих компиляторов в составе программного
обеспечения компьютера, на котором предполагается использовать данное
приложение, а также совместимости на уровне библиотек и системных вызовов. При
этом необходима перекомпиляция исходных текстов программ в новые исполняемые
модули.
Таким образом,
совместимость на уровне исходных текстов наиболее важное значение имеет для
разработчиков приложений, в распоряжении которых находятся эти исходные тексты.
Для конечных же пользователей практическое значение имеет только двоичная
совместимость, так как только в этом случае они могут без специальных навыков и
умений использовать программный продукт, поставляемый в виде двоичного
исполняемого кода, в различных операционных средах и на разных компьютерах. Для
пользователя, купившего в свое время пакет программ для MS-DOS, важно, чтобы он
мог запускать этот привычный ему пакет без каких-либо изменений или ограничений
на своей новой машине, работающей, например, под управлением Windows NT.
Множественные прикладные среды как раз и обеспечивают совместимость данной ОС с
приложениями, написанными для других ОС и процессоров, на двоичном уровне, а не
на уровне исходных текстов.
Каким типом
совместимости – двоичной или совместимостью исходных текстов обладает ОС,
зависит от многих факторов. Самый значительный из них – архитектура процессора,
на котором работает ОС. Только в том случае, если процессор использует тот же
набор команд (возможно, даже более расширенный, но ни в коем случае не
уменьшенный) и тот же диапазон адресов, двоичная совместимость может быть
достигнута довольно просто. Достаточно соблюсти несколько следующих условий:
- вызовы функций API,
которые содержит приложение, должны поддерживаться данной ОС;
- внутренняя структура
исполняемого файла приложения должна соответствовать структуре исполняемых
файлов данной ОС.
Несравнимо сложнее
достигнуть двоичной совместимости операционным системам, предназначенным для
выполнения на процессорах, имеющих различающиеся архитектуры. Кроме соблюдения
приведенных выше условий, необходимо также организовать эмуляцию двоичного
кода.
Способы реализации совместимости
Во многих версиях ОС
UNIX транслятор прикладных сред реализуется в виде обычного приложения. В таких
ОС, построенных с использованием микроядерной концепции, как, например Windows
NT или Workspace OS, прикладные среды выполняются в виде серверов
пользовательского режима. А в OS/2 с ее более простой архитектурой средства
организации прикладных сред встроены глубоко в ОС.
Стандартная многоуровневая структура ОС является основой для наиболее
очевидного варианта реализации множественных прикладных сред. На рис. 9
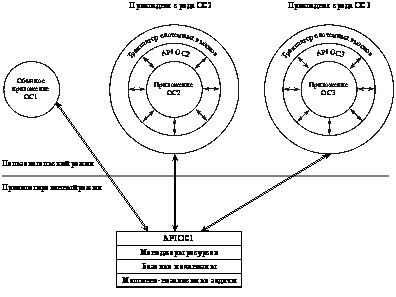
операционная система ОС1 поддерживает кроме своих “родных” приложений
приложения операционных систем ОС2 и ОС3. Для этого в ее составе имеются специальные приложения –
прикладные программные среды, которые транслируют интерфейсы “чужих”
операционных систем API ОС2 и API ОС3 в интерфейс своей “родной” операционной
системы API ОС1. Так, например, в случае, если бы в качестве ОС2 выступала
операционная система UNIX, а в качестве OC1 – OS/2, для выполнения системного
вызова создания процесса fork() в UNIX-приложении программная среда должна была
обратиться к ядру операционной системы OS/2 с системным вызовом DosExecPgm().
Трудности при такой реализации возникают вследствие того, что поведение
почти всех функций, составляющих API одной ОС, как правило, существенно
отличается от поведения соответствующих (если они вообще есть) функций другой
ОС. Например, чтобы функция создания процесса в OS/2 DosExecPgm() полностью
соответствовала функции создания процесса fork() в UNIX-подобных системах, ее
нужно изменить таким образом, чтобы она поддерживала возможность копирования
адресного пространства родительского процесса в пространство процесса-потомка,
хотя при нормальном поведении этой функции память процесса-потомка
инициализируется на основе данных нового исполняемого файла.
Другой вариант реализации множественных прикладных сред подразумевает
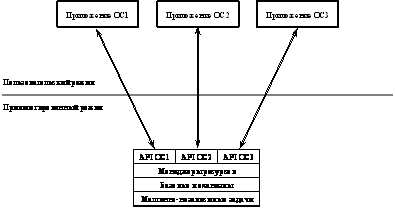
наличие в ОС нескольких равноправных прикладных программных интерфейсов. В
приведенном на рис. 10 примере операционная система поддерживает приложения,
написанные для ОС1, ОС2 и ОС3. Это достигается путем размещения непосредственно
в пространстве ядра системы прикладных программных интерфейсов всех этих ОС:
API ОС1, API ОС2 и API ОС3. В этом
варианте функции уровня API обращаются к функциям нижележащего уровня ОС,
которые должны поддерживать все три в общем случае несовместимые прикладные
среды. Несмотря на то, что в разных ОС по-разному осуществляется управление
системным временем, используется разный формат времени дня, на основании
собственных алгоритмов разделяется процессорное время и т.д., функции каждого
прикладного программного интерфейса реализуются с учетом специфики соответствующей
ОС. Для каждой ОС будет полностью реализован свой прикладной интерфейс
даже в том случае, если некоторые из
функций различных интерфейсов имеют
аналогичное назначение. Выбор того или иного варианта API осуществляется на
основании идентифицирующих характеристик, передаваемых в ядро соответствующим
процессом.
 Естественно, существует и способ построения
множественных прикладных сред, использующий концепцию микроядерного подхода.
При этом крайне важно отделить базовые, общие для всех прикладных сред, механизмы
ОС от специфических для каждой из прикладных сред высокоуровневых функций,
решающих стратегические задачи. В соответствии с микроядерной архитектурой все
функции ОС реализуются микроядром и серверами пользовательского режима. Важно
заметить, что каждая прикладная среда оформляется в виде отдельного сервера
пользовательского режима и не включает базовых механизмов (рис. 11).
Приложения, используя API, обращаются с системными вызовами к соответствующей
прикладной среде через микроядро. Прикладная среда обрабатывает запрос,
выполняет его (возможно, обращаясь для этого за помощью к базовым функциям
микроядра) и отсылает приложению результат. В ходе выполнения запроса
прикладной среде приходится, в свою очередь, обращаться к базовым механизмам
ОС, реализуемым микроядром и другими серверами ОС.
Естественно, существует и способ построения
множественных прикладных сред, использующий концепцию микроядерного подхода.
При этом крайне важно отделить базовые, общие для всех прикладных сред, механизмы
ОС от специфических для каждой из прикладных сред высокоуровневых функций,
решающих стратегические задачи. В соответствии с микроядерной архитектурой все
функции ОС реализуются микроядром и серверами пользовательского режима. Важно
заметить, что каждая прикладная среда оформляется в виде отдельного сервера
пользовательского режима и не включает базовых механизмов (рис. 11).
Приложения, используя API, обращаются с системными вызовами к соответствующей
прикладной среде через микроядро. Прикладная среда обрабатывает запрос,
выполняет его (возможно, обращаясь для этого за помощью к базовым функциям
микроядра) и отсылает приложению результат. В ходе выполнения запроса
прикладной среде приходится, в свою очередь, обращаться к базовым механизмам
ОС, реализуемым микроядром и другими серверами ОС.
Такому подходу к конструированию множественных прикладных средств
присущи все достоинства и недостатки микроядерной архитектуры, в частности:
- очень просто можно добавлять и исключать прикладные
среды, что является следствием хорошей расширяемости микроядерных ОС;
- надежность и стабильность выражаются в том, что при
отказе одной из прикладных сред все остальные сохраняют работоспособность;
- низкая производительность микроядерных ОС сильно
сказывается на скорости работы прикладных сред, а значит, и на скорости
выполнения приложений.
Создание в рамках одной ОС нескольких прикладных сред для выполнения
приложений различных ОС представляет собой путь, который позволяет иметь
единственную версию программы и переносить ее между ОС. Множественные
прикладные среды обеспечивают совместимость на двоичном уровне данной ОС с
приложениями, написанными для других ОС. В результате пользователи получают
большую свободу выбора ОС и более легкий доступ к качественному программному обеспечению.
Однако следует заметить, что реализация совместимости прикладных сред ОС,
кардинально отличающихся используемым аппаратным обеспечением, весьма
трудоемкая и сложная работа, а эффект от нее может оказаться слишком малым.
К усовершенствованным ОС, явно содержащим средства множественных
прикладных сред, относятся: IBM OS/2 2.x и Workplace OS, Microsoft Windows NT,
PowerOpen компании PowerOpen Association, версии UNIX от Sun Microsystems, IBM
и Hewlett-Packard. Кроме того, некоторые компании переделывают свои интерфейсы
пользователя в модули прикладных сред, а другие предлагают продукты для
эмуляции и трансляции прикладных сред, работающие в качестве прикладных
программ.
Рассмотрим, каким образом реализуются множественные прикладные
среды в уже описанной нами ранее ОС
Windows NT. При разработке NT важнейшим рыночным требованием являлось
обеспечение поддержки по крайней мере двух уже существующих на то время
программных интерфейсов – OS/2 и POSIX, а также возможности достаточно легкого
добавления других API в будущем.
Как уже отмечалось, для того чтобы
программа, написанная для одной ОС, могла быть выполнена в рамках другой ОС,
недостаточно лишь совместимости API.
Кроме этого, ей необходимо “родное” окружение: структура процесса, средства
управления памятью, средства обработки ошибок и исключительных ситуаций,
механизмы защиты ресурсов и семантика файлового доступа. Отсюда ясно, что
поддержка нескольких прикладных программных сред является очень непростой
задачей, тесно связанной со структурой ОС. Эта задача была успешно решена в
Windows NT, при этом в полной мере использовался опыт разработчиков ОС Mach из
университета Карнеги-Меллона, которые смогли в своей клиент-серверной
реализации UNIX отделить базовые механизмы ОС от серверов API различных операционных
систем.
Windows NT поддерживает
пять прикладных сред операционныхсистем: MS-DOS, 16-разрядный Windows, OS/2
1.x, POSIX и 32-разрядный Windows (Win32). Все пять прикладных сред реализованы
как подсистемы окружения. Каждая работает в собственном защищенном
пользовательском пространстве. Подсистема Win32 обеспечивает поддержку дисплея,
клавиатуры и мыши для четырех оставшихся подсистем.
16-битовые приложения DOS и Windows работают на VDM (virtual DOS
machines – виртуальные машины DOS), каждая из которых эмулирует полный 80x86
процессор с MS-DOS. В NT VDM является приложением Win32, значит, как и обычные
модули прикладных сред для UNIX, приложения DOS и 16-битовой Windows
расположены в слое непосредственно над подсистемой Win32.
Подсистемы OS/2 и POSIX построены по-другому. В качестве полноценных
подсистем NT они могут взаимодействовать с подсистемой Win32 для получения
доступа к вводу и выводу, но также могут обращаться непосредственно к
исполнительной системе NT за другими средствами ОС. Подсистема OS/2 может
выполнять многие имеющиеся приложения OS/2 символьного режима, включая OS/2 SQL
Server, а также поддерживает именованные каналы и NetBIOS.
Однако возможности подсистемы POSIX весьма ограничены, несмотря на
непосредственный доступ ее к службам ядра. Приложения POSIX должны быть
откомпилированы специально для Windows NT. NT не работает двоичным кодом,
предназначенным для таких POSIX-совместимых систем, как UNIX. К тому же
подсистема POSIX NT не поддерживает печать, сетевой доступ, за исключением доступа
к удаленным файловым системам, и многие другие средства Win32, например,
отображение на память файлов и графику.
NT executive выполняет базовые
функции ОС и является той основой, на которой подсистемы окружения реализуют
свои приложения. Все подсистемы равноправны и могут вызывать “родные” функции
NT для создания соответствующей среды приложений.
12,13,14-1 Основные понятия
Подсистема управления процессами является одной из
наиболее важных в операционной системе. В ее функции входит создание,
уничтожение и обеспечение взаимодействия между процессами, а также
распределение между ними процессорного времени. Определим понятия процесса и
потока. В юните “Основы операционных систем” уже было дано простейшее
определение процесса. Однако начиная с
1960-х годов в вычислительных системах используется мультипрограммирование,
или мультизадачность (multitasking) – способ организации вычислительного
процесса, при котором на одном процессоре выполняются сразу несколько программ.
В совместном использовании этих программ находятся и другие ресурсы системы:
оперативная память, дисковое пространство, данные.
Основными критериями для
оценки эффективности вычислительной
системы являются:
- пропускная
способность – количество задач, выполняемых вычислительной системой в
единицу времени;
- удобство работы
пользователей, заключающееся, например, в том, что они могут одновременно
работать в интерактивном режиме с несколькими приложениями на одном компьютере;
- реактивность
системы.
Для поддержки
мультипрограммирования в операционной системе (ОС) определяются внутренние
единицы работы, между которыми и разделяются ресурсы. В настоящее время в
большинстве операционных систем определены два типа единиц работы. Под процессом
(задачей) при этом понимается более крупная единица работы, требующая
для своего выполнения несколько единиц более мелких работ, называемых “поток”,
или “нить”. Объясним принципиальные
различия, существующие между этими понятиями.
В самом простейшем
случае процесс может состоять только из одного потока и тогда понятие “процесс”
полностью включает в себя понятие “поток” и остается только один вид единицы
работы и потребления всех ресурсов вычислительной системы – процесс.
Мультипрограммирование осуществляется в таких ОС на уровне процессов.
Каждый процесс должен
иметь возможность влиять только на принадлежащие ему коды и данные, поэтому в
задачи ОС при управлении процессами входит изоляция одного процесса от другого.
Реализация этих задач подразумевает выделение операционной системой каждому
процессу виртуального адресного пространства – совокупность адресов,
которыми может манипулировать программный модуль процесса. Отображение этого
виртуального пространства на реальную отведенную данному процессу физическую
память также осуществляется операционной системой. В тех случаях, когда
нескольким процессам необходимо взаимодействовать, например с целью обмена
данными, они обращаются к операционной системе, которая, выполняя функции
посредника, предоставляет им средства межпроцессной связи.
Потоки
возникли в операционных системах как средство распараллеливания вычислений.
Конечно, задача распараллеливания вычислений в рамках одного приложения может
быть решена и традиционными способами.
Во-первых,
прикладной программист может взять на себя сложную задачу организации
параллелизма, выделив в приложении некоторую подпрограмму-диспетчер, которая
периодически передает управление той или иной ветви вычислений. При этом
программа получается логически весьма запутанной, с многочисленными передачами
управления, что существенно затрудняет ее отладку и модификацию.
Во-вторых,
решением является создание для одного приложения нескольких процессов для
каждой из параллельных работ. Однако использование для создания процессов
стандартных средств ОС не позволяет учесть тот факт, что эти процессы решают
единую задачу, а значит, имеют много общего между собой – они могут работать с
одними и теми же данными, использовать один и тот же кодовый сегмент,
наделяться одними и теми же правами доступа к ресурсам вычислительной системы.
Таким
образом, в операционной системе наряду с процессами нужен другой механизм
распараллеливания вычислений, который учитывал бы тесные связи между
отдельными ветвями вычислений одного и того же приложения. Для этих целей
современные ОС предлагают механизм мпогопоточной обработки (multithreading).
При этом вводится новая единица работы – поток выполнения, а понятие “процесс”
в значительной степени меняет смысл. Понятию “поток” соответствует
последовательный переход процессора от одной команды программы к другой. ОС
распределяет процессорное время между потоками. Процессу ОС назначает адресное
пространство и набор ресурсов, которые совместно используются всеми его
потоками.
Создание
потоков, а не процессов, требует от ОС меньших накладных расходов. В отличие от
процессов, которые принадлежат разным, вообще говоря, конкурирующим
приложениям, все потоки одного процесса всегда принадлежат одному приложению,
поэтому ОС изолирует потоки в гораздо меньшей степени, нежели процессы в
традиционной мультипрограммной системе. Все потоки одного процесса используют
общие файлы, таймеры, устройства, одну и ту же область оперативной памяти,
одно и то же адресное пространство. Это означает, что они разделяют одни и те
же глобальные переменные. Поскольку каждый поток может иметь доступ к любому
виртуальному адресу процесса, один поток может использовать стек другого
потока. Между потоками одного процесса нет полной защиты, потому что,
во-первых, это невозможно, а во-вторых, не нужно. Чтобы организовать
взаимодействие и обмен данными, потокам вовсе не требуется обращаться к ОС, им
достаточно использовать общую память – один поток записывает данные, а другой
читает их. С другой стороны, потоки разных процессов по-прежнему хорошо
защищены друг от друга.
Итак,
мультипрограммирование более эффективно на уровне потоков, а не процессов.
Каждый поток имеет собственный счетчик команд и стек. Задача, оформленная в
виде нескольких потоков в рамках одного процесса, может быть выполнена быстрее
за счет псевдопараллельного (или параллельного в мультипроцессорной системе)
выполнения ее отдельных частей. Например, если электронная таблица была
разработана с учетом возможностей многопоточной обработки, то пользователь
может запросить пересчет своего рабочего листа и одновременно продолжать
заполнять таблицу. Особенно эффективно можно использовать многопоточность для
выполнения распределенных приложений, например многопоточный сервер может
параллельно выполнять запросы сразу нескольких клиентов.
Использование
потоков связано не только со стремлением повысить производительность системы
за счет параллельных вычислений, но и с целью создания более читабельных,
логичных программ. Введение нескольких потоков выполнения упрощает
программирование. Например, в задачах типа “писатель-читатель” один поток
выполняет запись в буфер, а другой считывает записи из него. Поскольку они
разделяют общий буфер, не стоит их делать отдельными процессами. Другой пример
использования потоков – управление сигналами, такими, как прерывание с
клавиатуры (del или break). Вместо обработки сигнала прерывания один поток
назначается для постоянного ожидания поступления сигналов. Таким образом,
использование потоков может сократить необходимость в прерываниях
пользовательского уровня. В этих примерах не столь важно параллельное
выполнение, сколь важна ясность программы.
Управление процессором в однопрограммном режиме
Рассмотрим задачу
управления процессором для однопрограммных операционных систем. В такой ОС
существует два процесса: системный процесс – процесс выполнения
программ ОС и пользовательский
процесс – процесс выполнения программ пользователя.
Системный процесс
существует постоянно: с момента загрузки операционной системы и до конца ее
работы. Он может быть заблокирован (например, ждать команды пользователя на
выполнение программы).
Переключение
“пользовательский процесс – системный процесс” в однопрограммной ОС связано со
следующими событиями в вычислительной системе:
- завершение
пользовательского процесса;
- обращение
пользовательского процесса к системному процессу для выполнения каких-либо
функций ОС.
Переключение “системный
процесс – пользовательский процесс” связано с:
- созданием
пользовательского процесса;
- завершением выполнения
функций ОС, используемых пользовательским процессом.
С точки зрения
процессора разделение процессов на системный и пользовательский является
абстрактным, поскольку процессору, как техническому устройству, безразлично,
команды какой программы он выполняет: пользовательской или системной.
Управление процессором в режиме
мультипрограммирования
Понятие мультипрограммирования
Операционные системы, поддерживающие
мульти-програм-мирование, в зависимости от выбранного критерия эффективности
вычислительной системы можно разделить на несколько основных типов: системы пакетной обработки, системы разделения
времени и системы реального времени. Некоторые операционные системы могут
поддерживать одновременно несколько режимов, например часть задач может
выполняться в режиме пакетной обработки, а часть – в режиме реального времени
или в режиме разделения времени.
Мультипрограммирование в системах пакетной
обработки
Рациональный режим
функционирования в системах пакетной обработки достигается благодаря
использованию следующей схемы функционирования: в начале работы формируется
пакет заданий, каждое задание содержит требование к системным ресурсам; из
этого пакета заданий формируется мультипрограммная смесь, т.е.
множество одновременно выполняемых задач. Причем смесь строится таким образом,
что одновременно должны выполняться задачи, предъявляющие разные требования к
ресурсам с целью обеспечения сбалансированной загрузки всех устройств
вычислительной машины. Например, в мультипрограммной смеси желательно
одновременное присутствие вычислительных задач и задач с интенсивным
вводом-выводом. Таким образом, выбор нового задания из пакета заданий зависит
от внутренней ситуации, складывающейся в системе, т.е. выбирается “выгодное” с
точки зрения критерия эффективности системы
задание. Следствием такой схемы организации мультипрограммирования в
вычислительных системах, работающих под управлением пакетных ОС, является
отсутствие гарантии выполнения какого-либо задания в течение определенного периода
времени.
Рассмотрим более
детально совмещение во времени операций ввода-вывода и вычислений.
Достигнуть
описанного выше совмещения можно несколькими способами. Один из них характерен
для компьютеров, имеющих специализированный процессор ввода-вывода. В
компьютерах класса мэйнфреймов такие процессоры называют каналами. Как
правило, канал имеет систему команд, отличающуюся от системы команд центрального
процессора. Эти команды специально предназначены для управления внешними
устройствами. Канальные программы могут храниться в той же оперативной памяти,
что и программы центрального процессора. Однако в системе команд центрального
процессора предусматривается специальная инструкция, с помощью которой каналу
передаются параметры и указания на то, какую программу ввода-вывода он должен
выполнить. Начиная с этого момента центральный процессор и канал могут работать
параллельно (рис.1,а).
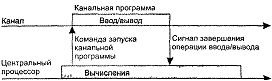 ис. 1. Параллельное
выполнение вычислений и операций ввода-вывода
ис. 1. Параллельное
выполнение вычислений и операций ввода-вывода
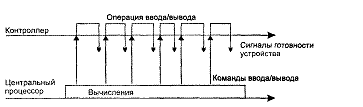 Существует и другой способ совмещения вычислений с
операциями ввода-вывода. Он реализован в компьютерах, управление внешними
устройствами в которых осуществляется так называемыми контроллерами. Каждое
внешнее устройство (или группа внешних устройств одного типа) имеет свой
собственный контроллер, который автономно отрабатывает команды, поступающие от
центрального процессора. При этом контроллер и центральный процессор работают
асинхронно. Многие внешние устройства включают электромеханические узлы,
вследствие чего контроллер выполняет свои команды управления устройствами
существенно медленнее, чем центральный процессор свои. Именно это
обстоятельство используется для организации параллельного выполнения вычислений
и операций ввода-вывода: в промежутке между передачей команд контроллеру
центральный процессор может выполнять вычисления (рис.1,б). Контроллер
может сообщить центральному процессору о том, что он готов принять следующую
команду, с помощью специального сигнала,
либо центральный процессор узнает
об этом, периодически опрашивая состояние контроллера.
Существует и другой способ совмещения вычислений с
операциями ввода-вывода. Он реализован в компьютерах, управление внешними
устройствами в которых осуществляется так называемыми контроллерами. Каждое
внешнее устройство (или группа внешних устройств одного типа) имеет свой
собственный контроллер, который автономно отрабатывает команды, поступающие от
центрального процессора. При этом контроллер и центральный процессор работают
асинхронно. Многие внешние устройства включают электромеханические узлы,
вследствие чего контроллер выполняет свои команды управления устройствами
существенно медленнее, чем центральный процессор свои. Именно это
обстоятельство используется для организации параллельного выполнения вычислений
и операций ввода-вывода: в промежутке между передачей команд контроллеру
центральный процессор может выполнять вычисления (рис.1,б). Контроллер
может сообщить центральному процессору о том, что он готов принять следующую
команду, с помощью специального сигнала,
либо центральный процессор узнает
об этом, периодически опрашивая состояние контроллера.
Таким
образом, для достижения максимальной эффективности решения задач операционной
системой необходимо обеспечить наиболее возможное совмещение вычислений и
ввода-вывода. Рассмотрим случай, когда процессор выполняет только одну задачу.
В этой ситуации степень ускорения зависит от природы данной задачи и от того,
насколько тщательно был выявлен возможный параллелизм при ее программировании.
В задачах, в которых преобладают либо вычисления, либо ввод-вывод, ускорение
почти отсутствует. Параллелизм в рамках одной задачи невозможен также, когда
для продолжения вычислений необходимо полное завершение операции ввода-вывода,
например, когда дальнейшие вычисления зависят от вводимых данных. В таких
случаях неизбежны простои центрального процессора или канала.
14-2 Мультипрограммирование в системах разделения
времени
В том случае, когда
критерием эффективности работы системы является удобство работы пользователя,
то применяется другой способ мультипрограммирования – разделения времени. В
системах разделения времени пользователям (или одному пользователю)
предоставляется возможность интерактивной работы сразу с несколькими
приложениями. Для этого каждое приложение должно регулярно получать возможность
“общения” с пользователем. Понятно, что в пакетных системах возможности диалога
пользователя с приложением весьма ограничены.
В системах разделения времени
эта проблема решается за счет того, что ОС принудительно периодически
приостанавливает приложения, не дожидаясь, когда они добровольно освободят
процессор. Всем приложениям попеременно выделяется квант процессорного
времени, вследствие чего пользователи, запустившие программы на выполнение,
получают возможность поддерживать с ними диалог.
В системах разделения
времени исправлен основной недостаток пакетной обработки – изолированность
пользователя от процесса выполнения его задач. Каждому пользователю в этом
случае предоставляется терминал, с которого он может вести диалог со своей
программой. Время ответа в таких системах оказывается вполне приемлемым для
пользователей, поскольку каждой задаче выделяется только квант процессорного
времени, а следовательно, ни одна задача не занимает процессор надолго.
Конечно, время реакции напрямую зависит от выбранного в системе кванта времени,
выделяемого каждому процессу. Если квант выбран достаточно небольшим, то у всех
пользователей, одновременно работающих на одной и той же машине, складывается
впечатление, что каждый из них единолично использует машину.
Одной из основных
причин, по которой системы разделения времени обладают меньшей пропускной
способностью, чем системы пакетной обработки,
является то, что на выполнение принимается каждая запущенная
пользователем задача, а не та, которая “выгодна” ОС. Кроме того,
производительность системы снижается из-за возросших накладных расходов
вычислительной мощности на более частое переключение процессора с задачи на
задачу. Это вполне соответствует тому, что критерием эффективности систем
разделения времени является не максимальная пропускная способность, а удобство
и эффективность работы пользователя. Вместе с тем мультипрограммное выполнение
интерактивных приложений повышает и пропускную способность компьютера (пусть и
не в такой степени, как пакетные системы). Аппаратура загружается лучше,
поскольку в то время, пока одно приложение ждет сообщения пользователя, другие
приложения могут обрабатываться процессором.
Мультипрограммирование в системах реального времени
Еще одна разновидность
мультипрограммирования используется в системах реального времени,
предназначенных для управления с помощью компьютера различными техническими
объектами (например, станком, спутником, научной экспериментальной установкой
и т. д.) или технологическими процессами. Во всех этих случаях существует предельно
допустимое время, в течение которого должна бытьвыполнена та или иная
управляющая объектом программа. В противном случае может произойти авария.
Таким образом, критерием эффективности здесь является время реакции системы.
Требования ко времени реакции зависят от специфики управляемого процесса. Контроллер
робота может требовать от встроенного компьютера ответ в течение менее 1 мс, в
то время как при моделировании полета может быть приемлем ответ в 40 мс.
В
системах реального времени мультипрограммная смесь отличается от рассмотренных
ранее и представляет собой фиксированный набор заранее разработанных программ,
а выбор программы на выполнение осуществляется исходя из текущего состояния
объекта или в соответствии с расписанием плановых работ.
Способность
аппаратуры компьютера и ОС к быстрому ответу зависит в основном от скорости
переключения с одной задачи на другую. Время переключения между задачами в
системах реального времени часто определяет требования к классу процессора даже
при небольшой его загрузке.
В системах реального
времени не стремятся максимально загружать все устройства, наоборот, при
проектировании программного управляющего комплекса обычно закладывается
некоторый “запас” вычислительной мощности на случай пиковой нагрузки. Во многих
ситуациях для систем управления неприменимы статистические гипотезы о малой
вероятности одновременного возникновения
большого количества независимых событий.
Например, в системе управления атомной электростанцией в случае
возникновения крупной аварии атомного реактора многие аварийные датчики
сработают одновременно и создадут коррелированную нагрузку. Если система
реального времени не спроектирована для поддержки пиковой нагрузки, то может
случиться так, что система не справится с работой именно тогда, когда она
нужна в наибольшей степени. большую память между всеми процессорами. Масштабируемость,
или возможность наращивания числа процессоров, в симметричных системах
ограничена вследствие того, что все они пользуются одной и той же оперативной
памятью и, следовательно, должны располагаться в одном корпусе. Такая конструкция,
называемая масштабируемой по вертикали, на практике ограничивает число
процессоров до четырех или восьми. В симметричных архитектурах все процессы
пользуются одной и той же схемой отображения памяти. Они могут очень быстро
обмениваться данными, так что обеспечивается достаточно высокая
производительность для тех приложений (например, при работе с базами данных), в
которых несколько задач должны активно взаимодействовать между собой.
В
асимметричной архитектуре разные процессоры могут отличаться как своими
характеристиками (производительностью, надежностью, системой команд и т.д.,
вплоть до модели микропроцессора), так и функциональной ролью, которая поручается
им в системе. Например, одни процессоры могут предназначаться для работы в
качестве основных вычислителей, другие – для управления подсистемой
ввода-вывода, третьи – еще для каких-то особых целей. Такая функциональная
неоднородность влечет за собой структурные отличия во фрагментах системы,
содержащих разные процессоры системы. Например, они могут отличаться схемами
подключения процессоров к системной шине, набором периферийных устройств и
способами взаимодействия процессоров с устройствами. Масштабирование в
асимметричной архитектуре реализуется иначе, чем в симметричной. Так как
требование единого корпуса отсутствует, система может состоять из нескольких
устройств, каждое из которых содержит один или несколько процессоров. Это
масштабирование по горизонтали. Каждое такое устройство называется кластером,
а вся мультипроцессорная система – кластерной.
Другим
аспектом мультипроцессорных систем, который может характеризоваться симметрией
или ее отсутствием, является способ организации вычислительного процесса.
Последний, как известно, определяется и реализуется операционной системой.
Асимметричное
мультипроцессирование – наиболее простой способ организации вычислительного
процесса в системах с несколькими процессорами. Этот способ часто называют
также “ведущий-ведомый”.
Функционирование
системы по принципу “ведущий-ведомый” предполагает выделение одного из
процессоров в качестве “ведущего”, на котором работает операционная система и
который управляет всеми остальными “ведомыми” процессорами, т.е. ведущий
процессор берет на себя функции распределения задач и ресурсов, а ведомые
процессоры работают только как обрабатывающие устройства и никаких действий по
организации работы вычислительной системы не выполняют.
Так
как операционная система работает только на одном процессоре и функции
управления полностью централизованы, то такая операционная система оказывается
не намного сложнее ОС однопроцессорной системы.
Асимметричная
организация вычислительного процесса может быть реализована как для
симметричной мультипроцессорной архитектуры, в которой все процессоры
аппаратно неразличимы, так и для несимметричной, для которой характерна
неоднородность процессоров, их специализация на аппаратном уровне.
В
системах с асимметричной архитектурой на роль ведущего процессора может быть
назначен наиболее надежный и производительный процессор. Если в наборе
процессоров имеется специализированный процессор, ориентированный, например,
на матричные вычисления, то при планировании процессов операционная система,
реализующая асимметричное мультипроцессирование, должна учитывать специфику
этого процессора. Такая специализация снижает надежность системы в целом, так
как процессоры не являются взаимозаменяемыми.
Симметричное
мультипроцессирование как способ организации вычислительного процесса может
быть реализовано в системах только с симметричной мультипроцессорной
архитектурой. Напомним, что в таких системах процессоры работают с общими
устройствами и разделяемой основной памятью.
Симметричное
мультипроцессирование реализуется общей для всех процессоров операционной
системой. При симметричной организации все процессоры равноправно участвуют и в
управлении вычислительным процессом, и в выполнении прикладных задач.
Например, сигнал от принтера, который распечатывает данные прикладного
процесса, выполняемого на некотором процессоре, может быть обработан совсем
другим процессором. Разные процессоры могут в какой-то момент одновременно
обслуживать как разные, так и одинаковые модули общей операционной системы.
Для этого программы операционной системы должны обладать свойством повторной
входимости (реентерабельностью). Операционная система при этом полностью
децентрализована. Модули ОС выполняются на любом доступном процессоре. Как
только процессор завершает выполнение очередной задачи, он передает управление
планировщику задач, который выбирает из общей для всех процессоров системной
очереди задачу, которая будет выполняться на данном процессоре следующей. Все
ресурсы выделяются для каждой выполняемой задачи по мере возникновения в них
потребностей и никак не закрепляются за процессором. При таком подходе все
процессоры работают с одной и той же динамически выравниваемой нагрузкой. В
решении одной задачи могут участвовать сразу несколько процессоров, если она
допускает такоераспараллеливание, например путем представления в виде
нескольких потоков.
В
случае отказа одного из процессоров симметричные системы, как правило,
сравнительно просто реконфигурируются, что является их большим преимуществом
перед плохо реконфигурируемыми асимметричными системами.
Симметричная и асимметричная
организация вычислительного процесса в мультипроцессорной системе не связана
напрямую с симметричной или асимметричной архитектурой, она определяется типом
операционной системы. Так, в симметричных архитектурах вычислительный процесс
может быть организован как симметричным образом, так и асимметричным. Однако
асимметричная архитектура непременно влечет за собой и асимметричный способ
организации вычислений.
15 МУЛЬТИПРОЦЕССОРНАЯ ОБРАБОТКА
Понятие
мультипроцессирования
Мультипроцессорная обработка – это способ организации вычислительного процесса в
системах с несколькими процессорами, при котором несколько задач (процессов,
потоков) могут одновременно выполняться на разных процессорах системы.
Концепция мультипроцессирования известна с 1970-х
годов, но до середины 80-х доступных многопроцессорных систем не существовало.
Однако к настоящему времени стало обычным включение нескольких процессоров в архитектуру
даже персонального компьютера. Более того, многопроцессорность теперь является
одним из необходимых требований, которые предъявляются к компьютерам,
используемым в качестве центрального сервера более-менее крупной сети.
Заметим, что следует различать мультипроцессорную и
мультипрограммную обработку. В мультипрограммных системах параллельная работа
разных устройств позволяет одновременно вести обработку нескольких программ, но
при этом в самом процессоре в каждый момент времени выполняется только одна
программа, т.е. несколько задач выполняются попеременно на одном процессоре,
создавая лишь видимость параллельного выполнения. В мультипроцессорных же
системах несколько задач выполняются действительно одновременно, так как
имеется несколько обрабатывающих устройств – процессоров. Конечно,
мультипроцессирование вовсе не исключает мультипрограммирования: на каждом из
процессоров может попеременно выполняться некоторый закрепленный за данным
процессором набор задач.
Усложнение архитектуры вычислительной системы за счет
увеличения числа процессоров приводит и к усложнению всех алгоритмов
управления ресурсами. Возрастает число конфликтов по обращению к устройствам
ввода-вывода, данным, общей памяти и совместно используемым программам.
Необходимо предусмотреть эффективные средства блокировки при доступе к
разделяемым информационным структурам ядра. Все эти проблемы должна решать
операционная система путем синхронизации процессов, ведения очередей и
планирования ресурсов. Более того, сама операционная система должна быть
спроектирована так, чтобы уменьшить существующие взаимозависимости между
собственными компонентами.
В наши дни становится общепринятым введение в ОС
функций поддержки мультипроцессорной обработки данных. Такие функции имеются во
всех популярных ОС, таких, как Sun Solaris 2.x, Santa Crus Operations Open
Server 3-х, IBM OS/2, Microsoft Windows NT и Novell NetWare, начиная с версии
4.1.
Симметричное
и асимметричное мультипроцессирование
Мультипроцессорные системы можно разделить на два
основных типа: симметричные и асимметричные. Причем это свойство может
характеризовать как тип архитектуры мультипроцессорной системы, так и способ
организации вычислительного процесса в этой системе.
Симметричная архитектура мультипроцессорной системы
предполагает однородность всех процессоров и единообразие их включения в общую
схему мультипроцессорной системы. Традиционные симметричные мультипроцессорные
конфигурации разделяют однубольшую память между всеми процессорами. Масштабируемость,
или возможность наращивания числа процессоров, в симметричных системах
ограничена вследствие того, что все они пользуются одной и той же оперативной
памятью и, следовательно, должны располагаться в одном корпусе. Такая конструкция,
называемая масштабируемой по вертикали, на практике ограничивает число
процессоров до четырех или восьми. В симметричных архитектурах все процессы
пользуются одной и той же схемой отображения памяти. Они могут очень быстро
обмениваться данными, так что обеспечивается достаточно высокая
производительность для тех приложений (например, при работе с базами данных), в
которых несколько задач должны активно взаимодействовать между собой.
В асимметричной
архитектуре разные процессоры могут отличаться как своими характеристиками
(производительностью, надежностью, системой команд и т.д., вплоть до модели
микропроцессора), так и функциональной ролью, которая поручается им в системе.
Например, одни процессоры могут предназначаться для работы в качестве основных
вычислителей, другие – для управления подсистемой ввода-вывода, третьи – еще
для каких-то особых целей. Такая функциональная неоднородность влечет за собой
структурные отличия во фрагментах системы, содержащих разные процессоры
системы. Например, они могут отличаться схемами подключения процессоров к
системной шине, набором периферийных устройств и способами взаимодействия
процессоров с устройствами. Масштабирование в асимметричной архитектуре
реализуется иначе, чем в симметричной. Так как требование единого корпуса
отсутствует, система может состоять из нескольких устройств, каждое из которых
содержит один или несколько процессоров. Это масштабирование по горизонтали.
Каждое такое устройство называется кластером, а вся мультипроцессорная
система – кластерной.
Другим аспектом
мультипроцессорных систем, который может характеризоваться симметрией или ее
отсутствием, является способ организации вычислительного процесса. Последний,
как известно, определяется и реализуется операционной системой.
Асимметричное
мультипроцессирование – наиболее простой способ организации вычислительного
процесса в системах с несколькими процессорами. Этот способ часто называют
также “ведущий-ведомый”.
Функционирование
системы по принципу “ведущий-ведомый” предполагает выделение одного из
процессоров в качестве “ведущего”, на котором работает операционная система и
который управляет всеми остальными “ведомыми” процессорами, т.е. ведущий
процессор берет на себя функции распределения задач и ресурсов, а ведомые
процессоры работают только как обрабатывающие устройства и никаких действий по
организации работы вычислительной системы не выполняют.
Так как
операционная система работает только на одном процессоре и функции управления
полностью централизованы, то такая операционная система оказывается не намного
сложнее ОС однопроцессорной системы.
Асимметричная
организация вычислительного процесса может быть реализована как для
симметричной мультипроцессорной архитектуры, в которой все процессоры
аппаратно неразличимы, так и для несимметричной, для которой характерна
неоднородность процессоров, их специализация на аппаратном уровне.
В системах с
асимметричной архитектурой на роль ведущего процессора может быть назначен
наиболее надежный и производительный процессор. Если в наборе процессоров
имеется специализированный процессор, ориентированный, например, на матричные
вычисления, то при планировании процессов операционная система, реализующая
асимметричное мультипроцессирование, должна учитывать специфику этого
процессора. Такая специализация снижает надежность системы в целом, так как
процессоры не являются взаимозаменяемыми.
Симметричное
мультипроцессирование как способ организации вычислительного процесса может
быть реализовано в системах только с симметричной мультипроцессорной
архитектурой. Напомним, что в таких системах процессоры работают с общими
устройствами и разделяемой основной памятью.
Симметричное мультипроцессирование реализуется общей
для всех процессоров операционной системой. При симметричной организации все
процессоры равноправно участвуют и в управлении вычислительным процессом, и в
выполнении прикладных задач. Например, сигнал от принтера, который
распечатывает данные прикладного процесса, выполняемого на некотором процессоре,
может быть обработан совсем другим процессором. Разные процессоры могут в
какой-то момент одновременно обслуживать как разные, так и одинаковые модули
общей операционной системы. Для этого программы операционной системы должны
обладать свойством повторной входимости (реентерабельностью). Операционная
система при этом полностью децентрализована. Модули ОС выполняются на любом
доступном процессоре. Как только процессор завершает выполнение очередной
задачи, он передает управление планировщику задач, который выбирает из общей для
всех процессоров системной очереди задачу, которая будет выполняться на данном
процессоре следующей. Все ресурсы выделяются для каждой выполняемой задачи по
мере возникновения в них потребностей и никак не закрепляются за процессором.
При таком подходе все процессоры работают с одной и той же динамически
выравниваемой нагрузкой. В решении одной задачи могут участвовать сразу
несколько процессоров, если она допускает такоераспараллеливание, например
путем представления в виде нескольких потоков.
В случае отказа
одного из процессоров симметричные системы, как правило, сравнительно просто
реконфигурируются, что является их большим преимуществом перед плохо
реконфигурируемыми асимметричными системами.
Симметричная и асимметричная организация
вычислительного процесса в мультипроцессорной системе не связана напрямую с
симметричной или асимметричной архитектурой, она определяется типом
операционной системы. Так, в симметричных архитектурах вычислительный процесс
может быть организован как симметричным образом, так и асимметричным. Однако
асимметричная архитектура непременно влечет за собой и асимметричный способ
организации вычислений.
16-1 ПЛАНИРОВАНИЕ
ПРОЦЕССОВ И ПОТОКОВ
Понятия
“процесс” и “поток”
Для того чтобы управлять
тем или иным процессом, он сначала должен быть создан. Создать процесс – это
прежде всего означает создать описатель процесса, в качестве которого
выступает одна или несколько информационных структур, содержащих все сведения о
процессе, необходимые операционной системе для управления им. В число таких
сведений могут входить, например, идентификатор процесса, данные о
расположении в памяти исполняемого модуля, степень привилегированности
процесса (приоритет и права доступа) и т. п. Примерами описателей процесса
являются блок управления задачей (ТСВ – Task Control Block) в OS/360,
управляющий блик процесса (РСВ – Process Control Block) в OS/2, дескриптор
процесса в UNIX, объект-процесс (object-process) в Windows NT. После создания
процесса в системе появляется новый претендент на вычислительные ресурсы,
потребности которого ОС обязана учитывать при
решении задач распределения ресурсов между процессами.
Создание процесса включает загрузку кодов и
данных исполняемой программы данного процесса с диска в оперативную память. Для
этого ОС должна обнаружить местоположение такой программы на диске,
перераспределить оперативную память и выделить память исполняемой программе нового
процесса. Затем необходимо считать программу в выделенные для нее участки
памяти и, возможно, изменить параметры программы в зависимости от размещения в
памяти. При выполнении всех этих действий подсистема управления процессами
тесно взаимодействует с подсистемой управления памятью и файловой системой.
В многопоточной системе
при создании процесса ОС создает для каждого процесса как минимум один поток
выполнения. При создании потока так же, как и при создании процесса,
операционная система генерирует специальную информационную структуру – описатель
потока, который содержит идентификатор потока, данные о правах доступа и
приоритете, о состоянии потока и другую информацию. В исходном состоянии поток
(или процесс, если речь идет о системе, в которой понятие “поток” не
определяется) находится в приостановленном состоянии. Момент выборки потока на
выполнение осуществляется в соответствии с принятым в данной системе правилом
предоставления процессорного времени и с учетом всех существующих в данный
момент потоков и процессов.
Рассмотрим в качестве
примера создание процессов в популярной версии операционной системы UNIX
System V Release 4. В этой системе потоки не поддерживаются, в качестве
единицы управления и единицы потребления ресурсов выступает только процесс.
При управлении
процессами операционная система использует два основных типа информационных
структур: дескриптор процесса и контекст процесса. Дескриптор
процесса содержит такую информацию о процессе, которая необходима ядру в
течение всего жизненного цикла процесса независимо от того, находится он в
активном или пассивном состоянии, находится образ процесса в оперативной памяти
или выгружен на диск. Образ процесса – совокупность его кодов и данных.
Дескрипторы отдельных
процессов объединены в список, образующий таблицу процессов. Память для
таблицы процессов отводится динамически в области ядра. На основании
информации, содержащейся в таблице процессов, операционная система осуществляет
планирование и синхронизацию процессов. В дескрипторе прямо или косвенно (через
указатели, не связанные спроцессом структуры) содержится информация о
состоянии процесса, о расположении образа процесса в оперативной памяти и на
диске, о значении отдельных составляющих приоритета, а также о его итоговом
значении – глобальном приоритете, об идентификаторе пользователя, создавшего
процесс, о родственных процессах, о событиях, осуществления которых ожидает
данный процесс, и некоторая другая информация.
Контекст процесса содержит менее
оперативную, но более объемную часть информации о процессе, необходимую для
возобновления выполнения процесса с прерванного места: содержимое регистров
процессора, коды ошибок, выполняемых процессором системных вызовов, информация
обо всех открытых данным процессом файлах и незавершенных операциях
ввода-вывода и другие данные, характеризующие состояние вычислительной среды в
момент прерывания. Контекст, так же как и дескриптор процесса, доступен только
программам ядра, т.е. находится в виртуальном адресном пространстве
операционной системы, однако он хранится не в области ядра, а непосредственно
примыкает к образу процесса и перемещается вместе с ним, если это необходимо,
из оперативной памяти на диск.
Порождение процессов в
системе UNIX происходит в результате выполнения системного вызова fork. ОС
строит образ порожденного процесса, являющийся точной копией образа породившего
процесса, т.е. дублируются дескриптор, контекст и образ процесса. Сегмент
данных и сегмент стека родительского процесса копируются на новое место,
образуя сегменты данных и стека процесса-потомка. Процедурный сегмент
копируется только тогда, когда он не является разделяемым. В противном случае
процесс-потомок становится еще одним процессом, разделяющим данный процедурный
сегмент.
После выполнения
системного вызова fork оба процесса продолжают выполнение с одной и той же
точки. Чтобы процесс мог опознать, является он родительским процессом или
процессом-потомком, системный вызов fork возвращает в качестве своего значения
в породивший процесс идентификатор порожденного процесса, а в порожденный
процесс – NULL. Идентификатор потомка может быть присвоен переменной, входящей
в контекст родительского процесса. Так как контекст процесса наследуется его
потомками, то потомки могут узнать идентификаторы своих “старших братьев”,
таким образом сумма знаний наследуется при порождении и может быть
распространена между родственными процессами. На независимости идентификатора
процесса от выполняемой процессом программы построен механизм, позволяющий процессу
перейти к выполнению другой программы с помощью системного вызова ехес.
Таким образом, в UNIX
порождение нового процесса происходит в два этапа – сначала создается копия
процесса-родителя, затем у нового процесса производится замена кодового
сегмента на заданный.
Вновь созданному
процессу операционная система присваивает целочисленный идентификатор,
уникальный на весь период функционирования системы.
Планирование и диспетчеризация потоков
Планирование и
диспетчеризация потоков является основой для перехода от выполнения одного
потока к другому в процессе функционирования операционной системы. Работа по
определению того, в какой момент необходимо прервать выполнение текущего
активного потока и какому потоку предоставить возможность выполняться,
называется планированием. Планирование потоков осуществляется на основе
информации, хранящейся в описателях процессов и потоков. При планировании могут
приниматься во внимание приоритет потоков, время их ожидания в очереди, накопленное
время выполнения, интенсивность обращений к вводу-выводу и другие факторы. ОС
планирует выполнение потоков в независимости от их принадлежности одному или
разным процессам. Так, например, после выполнения потока некоторого процесса ОС
может выбрать для выполнения другой поток того же процесса или же назначить к
выполнению поток другого процесса. Выбор того или иного потока в первую очередь
будет определяться алгоритмом планирования, применяемым в данной ОС, текущей
ситуацией в системе и критерием эффективности функционирования системы.
Планирование потоков, по существу, включает в себя решение двух задач:
- определение момента
времени для смены текущего активного потока;
- выбор для выполнения
потока из очереди готовых потоков.
Планирование
в операционных системах может осуществляться как во время работы, так и
заранее. В большинстве операционных систем универсального назначения
планирование осуществляется динамически (on-line), т.е. решения
принимаются во время работы системы на основе анализа текущей ситуации. В этом
случае ОС всегда работает в условиях неопределенности – потоки и процессы
появляются в случайные моменты времени и также непредсказуемо завершаются.
Динамические планировщики могут гибко приспосабливаться к изменяющейся ситуации
и не используют никаких предположений о мультипрограммной смеси. Для того чтобы
оперативно найти в условиях такой неопределенности оптимальный в некотором
смысле порядок выполнения задач, операционная система должна затрачивать
значительные усилия.
Другой
тип планирования – статический – может быть использован в специализированных
системах, в которых весь набор одновременно выполняемых задач определен
заранее, например в системах реального времени. Планировщик называется
статическим (или предварительным планировщиком), если он принимает решения о
планировании не во время работы системы, а заранее (off-line). Соотношение
между динамическим и статическим планировщиками аналогично соотношению между
диспетчером железной дороги, который пропускает поезда строго по предварительно
составленному расписанию, и регулировщиком на перекрестке автомобильных дорог,
не оснащенном светофорами, который решает, какую машину остановить, а какую
пропустить, в зависимости от ситуации на перекрестке.
Результатом
работы статического планировщика является таблица, называемая расписанием,
в которой указывается, какому потоку/процессу, когда и на какое время должен
быть предоставлен процессор. Для построения расписания планировщику нужны как
можно более полные предварительные знания о характеристиках набора задач,
например о максимальном времени выполнения каждой задачи, ограничениях
предшествования, ограничениях по взаимному исключению, предельным срокам и т.д.
После
того как расписание готово, оно может использоваться операционной системой для
переключения потоков и процессов. При этом накладные расходы ОС на исполнение
расписания оказываются значительно меньшими, чем при динамическом
планировании, и сводятся лишь к диспетчеризации потоков/процессов.
Диспетчеризация заключается в реализации найденного в результате
планирования (динамического или статического) решения, т.е. в переключении процессора
с одного потока на другой. Переключение между процессами сопровождается в
системе определенными действиями. Прежде всего ОС запоминает контекст
выполняемого в данный момент потока, чтобы впоследствии использовать эту информацию
для последующего возобновления выполнения данного потока. Контекст отражает,
во-первых, состояние аппаратуры компьютера в момент прерывания потока (значение
счетчика команд, содержимое регистров общего назначения, режим работы
процессора, флаги, маски прерываний и другие параметры). Во-вторых, контекст
включает параметры операционной среды, а именно ссылки на открытые файлы,
данные о незавершенных операциях ввода-вывода, коды ошибок выполняемых данным
потоком системных вызовов и т.д. Диспетчеризация сводится к следующему:
- сохранение контекста текущего потока, который
требуется сменить;
- загрузка контекста нового потока, выбранного в
результате планирования;
- запуск нового потока на выполнение.
Поскольку
операция переключения контекстов существенно влияет на производительность
вычислительной системы, программные модули ОС выполняют диспетчеризацию потоков
совместно с аппаратными средствами процессора.
Поскольку
поток является частью процесса, то в контексте потоков одного процесса можно
выделить общую информацию для всех потоков одного процесса (например, ссылки на
открытые файлы) и информацию, относящуюся только к данному потоку (например,
содержимое регистров, счетчик команд, режим процессора). Например, в среде
NetWare 4.х различаются три вида контекстов: глобальный контекст (контекст
процесса), контекст группы потоков и контекст отдельного потока. Соотношение
между данными этих контекстов напоминает соотношение глобальных и локальных
переменных в программе, написанной на языке С. Переменные глобального
контекста доступны для всех потоков, созданных в рамках одного процесса.
Переменные локального контекста доступны только для кодов определенного потока,
аналогично локальным переменным функции. В NetWare можно создавать несколько
групп потоков внутри одного процесса и эти группы будут иметь свой групповой
контекст. Переменные, принадлежащие групповому контексту, доступны всем
потокам, входящим в группу, но недоступны остальным потокам. Очевидно, что
такая иерархическая организация контекстов ускоряет переключение потоков, так
как при переключении с потока на поток в пределах одной группы нет
необходимости заменять контексты групп или глобальные контексты, достаточно
лишь заменить контексты потоков, которые имеют меньший объем. Аналогично при
переключении с потока одной группы на поток другой группы в пределах одного
процесса глобальный контекст не изменяется, а изменяется лишь контекст группы.
Переключение же глобальных контекстов происходит только при переходе с потока
одного процесса на поток другого процесса.
Во многих операционных
системах встречаются компоненты, которые называются планировщик
(scheduler), или диспетчер(dispatcher). Не следует однозначно судить о
функциональном назначении этих компонентов по их названиям, т.е. считать, что
планировщик выполняет планирование, а диспетчер – диспетчеризацию в том
смысле, в котором эти функции были определены выше. Чаще всего оба этих
названия используются для обозначения компонентов, которые занимаются
планированием.
ОС
выполняет планирование потоков, принимая во внимание их состояние. В
мультипрограммной системе поток может находиться в одном из трех основных
состояний:
- выполнение
– активное состояние потока, во время которого поток обладает всеми
необходимыми ресурсами и непосредственно выполняется процессором;
- ожидание
– пассивное состояние потока, находясь в котором, поток заблокирован по своим
внутренним причинам (ждет осуществления некоторого события, например
завершения операции ввода-вывода, получения сообщения от другого потока или
освобождения какого-либо необходимого ему ресурса);
- готовность
– также пассивное состояние потока, но в этом случае поток заблокирован в
связи с внешним по отношению к нему обстоятельством (имеет все требуемые для
него ресурсы, готов выполняться, однако процессор занят выполнением другого
потока).
В
течение своей жизни каждый поток переходит из одного состояния в другое в
соответствии с алгоритмом планирования потоков, принятым в данной операционной
системе. Замена процесса, выполняемого процессором, называется переключением.
16-2 Перейдем к непосредственному рассмотрению алгоритмов планирования потоков. С
самых общих позиций все множество алгоритмов планирования можно разделить на
два класса: вытесняющие и
невытесняющие алгоритмы планирования. Невытесняющие
(non-preemptive) алгоритмы основаны на том, что активному потоку позволяется
выполняться, пока он сам, по собственной инициативе, не отдаст управление
операционной системе для того, чтобы та выбрала из очереди другой готовый к
выполнению поток. Вытесняющие (preemptive) алгоритмы – это такие
способы планирования потоков, в которых решение о переключении процессора с
выполнения одного потока навыполнение другого потока принимается операционной
системой, а не активной задачей.
Исходя
из определений, главным различием между вытесняющими и невытесняющими
алгоритмами является степень централизации механизма планирования потоков. При
вытесняющем мультипрограммировании функции планирования потоков целиком сосредоточены
в операционной системе и программист пишет свое приложение, не заботясь о том,
что оно будет выполняться одновременно с другими задачами. При этом
операционная система выполняет следующие функции: определяет момент снятия с
выполнения активного потока, запоминает его контекст, выбирает из очереди
готовых потоков следующий, запускает новый поток на выполнение, загружая его
контекст.
При
невытесняющем мультипрограммировании механизм планирования распределен между
операционной системой и прикладными программами. Прикладная программа, получив
управление от операционной системы, сама определяет момент завершения
очередного цикла своего выполнения и только затем передает управление ОС с
помощью какого-либо системного вызова. ОС формирует очереди потоков и выбирает
в соответствии с некоторым правилом (например, с учетом приоритетов) следующий
поток на выполнение. Такой механизм создает проблемы как для пользователей,
так и для разработчиков приложений. Пользователи при таком подходе теряют
управление системой на неопределенный период времени, который определяется
выполняемым в данный момент приложением. При этом в том случае, если приложение
тратит слишком много времени на выполнение какой-либо работы, например на
форматирование диска, пользователь не может переключиться с этой задачи на
другую, например на текстовый редактор, в то время как форматирование
продолжалось бы в фоновом режиме.
Почти
во всех современных операционных системах, ориентированных на высокопроизводительное
выполнение приложений (UNIX, Windows NT/2000, OS/2, VAX/VMS), реализованы
вытесняющие алгоритмы планирования потоков (процессов). В последнее время
дошла очередь и до ОС класса настольных систем, например OS/2 Warp и Windows
95/98.
В
основе многих вытесняющих алгоритмов планирования лежит концепция квантования.
В соответствии с этой концепцией каждому потоку поочередно для выполнения
предоставляется ограниченный непрерывный период процессорного времени – квант.
Смена активного потока происходит, если:
- поток завершился и покинул систему,
- произошла ошибка,
- поток перешел в состояние ожидания,
- исчерпан квант процессорного времени, отведенный
данному потоку.
Поток, который исчерпал
свой квант, переводится в состояние готовности и ожидает, когда ему будет
предоставлен новый квант процессорного времени, а на выполнение в соответствии
с определенным правилом выбирается новый поток из очереди готовых. Граф
состояний потока, изображенный на рис. 6, соответствует алгоритму планирования,
основанному на квантовании. Кванты, выделяемые потокам, могут быть одинаковыми
для всех потоков или различными. Рассмотрим, например, случай, когда всем
потокам предоставляются кванты одинаковой длины q (рис.7). Если в
системе имеется n потоков, то время, которое поток проводит в ожидании
следующего кванта, можно грубо оценить как q(n–1). Чем больше
потоков в системе, тем больше время ожидания, тем меньше возможности вести
одновременную интерактивную работу нескольким пользователям. Но если величина
кванта выбрана очень небольшой, то значение произведения q(n–1)
все равно будет достаточно мало для того, чтобы пользователь не ощущал
дискомфорта от присутствия в системе других пользователей. Типичное значение
кванта в системах разделения времени составляет десятки миллисекунд.
Если
квант короткий, то суммарное время, которое проводит поток в ожидании
процессора, прямо пропорционально времени, требуемому для его выполнения (т.е.
времени, которое потребовалось бы для выполнения этого потока при монопольном
использовании вычислительной системы). Действительно, поскольку время ожидания
между двумя циклами выполнения равно q(n–1), а количество циклов B/q,
где В – требуемое время выполнения, то W=B(n–1). Заметим,
что эти соотношения представляют собой весьма грубые оценки, основанные на
предположении, что В значительно превышает q. При этом не учитывается,
что потоки могут использовать кванты неполностью, что часть времени они могут
тратить на ввод-вывод, что количество потоков в системе может динамически
меняться и т.д.
Чем
больше квант, тем выше вероятность того, что потоки завершатся в результате
первого же цикла выполнения, и тем менее явной становится зависимость времени
ожидания потоков от их времени выполнения. При достаточно большом кванте алгоритм
квантования вырождается в алгоритм последовательной обработки, присущий
однопрограммным системам, при котором время ожидания задачи в очереди вообще
никак не зависит от ее длительности.
Кванты,
выделяемые одному потоку, могут быть фиксированной величины, а могут и
изменяться в разные периоды жизни потока. Пусть, например, первоначально
каждому потоку назначался достаточно большой квант, а величина каждого
следующего кванта уменьшается до некоторой заранее заданной величины. В таком
случае преимущество получают короткие задачи, которые успевают выполняться в
течение первого кванта, а длительные вычисления будут проводиться в фоновом
режиме. Можно представить себе алгоритм планирования, в котором каждый
следующий квант, выделяемый определенному потоку, больше предыдущего. Такой
подход позволяет уменьшить накладные расходы на переключение задач в том
случае, когда сразу несколько задач выполняют длительные вычисления.
Многозадачные
ОС теряют некоторое количество процессорного времени для выполнения вспомогательных
работ во время переключения контекстов задач. При этом запоминаются и
восстанавливаются регистры, флаги и указатели стека, а также проверяется
статус задач для передачи управления. Затраты на эти вспомогательные действия
не зависят от величины кванта времени, поэтому чем больше квант, тем меньше
суммарные накладные расходы, связанные с переключением потоков.
В
алгоритмах, основанных на квантовании, какую бы цель они не преследовали
(предпочтение коротких или длинных задач, компенсация недоиспользованного
кванта или минимизация накладных расходов, связанных с переключениями), не
используется никакой предварительной информации о задачах. При поступлении
задачи на обработку ОС не имеет никаких сведений о том, является ли она
короткой или длинной, насколько интенсивными будут ее запросы к устройствам
ввода-вывода, насколько важно ее быстрое выполнение и т.д.
Дифференциация обслуживания при квантовании базируется на “истории
существования” потока в системе.
Другой
важной концепцией, лежащей в основе многих вытесняющих алгоритмов
планирования, является приоритетное обслуживание. Приоритетное обслуживание
предполагает наличие у потоков некоторой изначально известной характеристики –
приоритета, на основании которой определяется порядок их выполнения. Приоритет
– это число, характеризующее степень привилегированности потока при
использовании ресурсов вычислительной машины, в частности процессорного
времени: чем выше приоритет, тем выше привилегии, тем меньше времени будет
проводить поток в очередях.
Приоритет
может выражаться целым или дробным, положительным или отрицательным значением.
В некоторых ОС принято, что приоритет потока тем выше, чем больше (в
арифметическом смысле) число, обозначающее приоритет. В других системах,
наоборот, чем меньше число, тем выше приоритет.
В
большинстве операционных систем, поддерживающих потоки, приоритет потока
непосредственно связан с приоритетом процесса, в рамках которого выполняется
данный поток. Приоритет процесса назначается операционной системой при его
создании. Значение приоритета включается в описатель процесса и используется
при назначении приоритета потокам этого процесса. При назначении приоритета
вновь созданному процессу ОС учитывает, является этот процесс системным или
прикладным, каков статус пользователя, запустившего процесс, было ли явное
указание пользователя на присвоение процессу определенного уровня приоритета.
Поток может быть инициирован не только по команде пользователя, но и в
результате выполнения системного вызова другим потоком. В этом случае при
назначении приоритета новому потоку ОС должна принимать во внимание значение
параметров системного вызова.
Во
многих ОС предусматривается возможность изменения приоритетов в течение жизни
потока. Изменения приоритета могут происходить по инициативе самого потока,
когда он обращается с соответствующим вызовом к операционной системе, или по
инициативе пользователя, когда он выполняет соответствующую команду. Кроме
того, ОС сама может изменять приоритеты потоков в зависимости от ситуации,
складывающейся в системе. В последнем случае приоритеты называются
динамическими в отличие от неизменяемых, фиксированных, приоритетов.
От
того, какие приоритеты назначены потокам, существенно зависит эффективность
работы всей вычислительной системы. В современных ОС во избежание
разбалансировки системы, которая может возникнуть при неправильном назначении
приоритетов, возможности пользователей влиять на приоритеты процессов и
потоков стараются ограничивать. При этом обычные пользователи, как правило, не
имеют права повышать приоритеты своим потокам, это разрешено делать (да и то в
определенных пределах) только администраторам. В большинстве же случаев ОС
присваивает приоритеты потокам по умолчанию.
В
качестве примера рассмотрим схему назначения приоритетов потокам, принятую в
операционной системе Windows NT (рис.9). В системе определено 32 уровня
приоритетов и два класса потоков – потоки реального времени и потоки с
переменными приоритетами. Диапазон от 1 до 15 включительно отведен для потоков
с переменными приоритетами, а от 16 до 31 – для более критичных ко времени
потоков реального времени (приоритет 0 зарезервирован для системных целей).
При
создании процесса он в зависимости от класса получает по умолчанию базовый
приоритет в верхней или нижней части диапазона. Базовый приоритет процесса в
дальнейшем может быть повышен или понижен операционной системой. Первоначально
поток получает значение базового приоритета из диапазона базового приоритета
процесса, в котором он был создан. Пусть, например, значение базового
приоритета некоторого процесса равно К. Тогда все потоки данного процесса
получат базовые приоритеты из диапазона [К–2, К+2]. Отсюда видно, что, изменяя
базовый приоритет процесса, ОС может влиять на базовые приоритеты его потоков.
В
Windows NT с течением времени приоритет потока, относящегося к классу потоков
с переменными приоритетами, может отклоняться от базового приоритета потока,
причем эти изменения могут быть не связаны с изменениями базового приоритета
процесса. ОС может повышать приоритет потока (который в этом случае называется
динамическим) в тех случаях, когда поток не полностью использовал отведенный
ему квант, или понижать приоритет, если квант был использован полностью. ОС
наращивает приоритет дифференцированно в зависимости от того, какого типа
событие не дало потоку полностью использовать квант. В частности, ОС повышает
приоритет в большей степени потокам, которые ожидают ввода с клавиатуры
(интерактивным приложениям) и в меньшей степени – потокам, выполняющим дисковые
операции. Именно на основе динамических приоритетов осуществляется
планирование потоков. Начальной точкой отсчета для динамического приоритета
является значение базового приоритета потока. Значение динамического
приоритета потока ограничено снизу его базовым приоритетом, верхней же границей
является нижняя граница диапазона приоритетов реального времени.
Существуют
две разновидности приоритетного планирования: обслуживание с относительными
приоритетами и обслуживание с абсолютными приоритетами.
В
обоих случаях выбор потока на выполнение из очереди готовых осуществляется
одинаково: выбирается поток, имеющий наивысший приоритет. Однако проблема
определения момента смены активного потока решается по-разному. В системах с
относительными приоритетами активный поток выполняется до тех пор, пока он сам
не покинет процессор, перейдя в состояние ожидания (или произойдет ошибка, или
поток завершится). На рис.10, а показан граф состояний потока в системе
с относительными приоритетами.
В
системах с абсолютными приоритетами выполнение активного потока прерывается,
кроме указанных выше причин, еще при одном условии: если в очереди готовых
потоков появился поток, приоритет которого выше приоритета активного потока. В
этом случае прерванный поток переходит в состояние готовности (рис.10, б).
В
системах, в которых планирование осуществляется на основе относительных
приоритетов, с одной стороны, минимизируются затраты на переключения процессора
с одной работы на другую. С другой стороны, здесь могут возникать ситуации,
когда одна задача занимает процессор долгое время. Ясно, что для систем
разделения времени и реального времени такая дисциплина обслуживания не
подходит: интерактивное приложение может ждать своей очереди часами, пока
вычислительной задаче не потребуется ввод-вывод. А вот в системах пакетной
обработки (в том числе известной ОС OS/360) относительные приоритеты
используются широко.
В
системах с абсолютными приоритетами время ожидания потока в очередях может быть
сведено к минимуму, если ему назначить самый высокий приоритет. Такой поток
будет вытеснять из процессора все остальные потоки (кроме потоков, имеющих
такой же наивысший приоритет). Это делает планирование на основе абсолютных
приоритетов подходящим для систем управления объектами, в которых важна быстрая
реакция на событие.
17-19
ПРЕРЫВАНИЯ
Назначение и типы прерываний
Прерывания являются основной
движущей силой любой операционной системы. Периодические прерывания от таймера
вызывают смену процессов в мультипрограммной ОС, а прерывания от устройств
ввода-вывода управляют потоками данных, которыми вычислительная система
обменивается с внешним миром.
Система прерываний
переводит процессор на выполнение потока команд, отличного от того, который
выполнялся до сих пор, с последующим возвратом к исходному коду. Из сказанного
можно сделать вывод о том, что механизм прерываний очень похож на механизм
выполнения процедур. Это на самом деле так, хотя между этими механизмами
имеется важное отличие. Переключение по прерыванию отличается от переключения,
которое происходит по команде безусловного или условного перехода,
предусмотренной программистом в потоке команд приложения. Переход по команде
происходит в заранее определенных программистом точках программы в зависимости
от исходных данных, обрабатываемых программой. Прерывание же происходит в
произвольной точке потока команд программы, которую программист не может
прогнозировать. Прерывание возникает либо в зависимости от внешних по
отношению к процессу выполнения программы событий, либо при появлении
непредвиденных аварийных ситуаций в процессе выполнения данной программы.
Сходство же прерываний с процедурами состоит в том, что в обоих случаях
выполняется некоторая подпрограмма, обрабатывающая специальную ситуацию, а
затем продолжается выполнение основной ветви программы.
В зависимости от
источника прерывания делятся на три больших класса:
- внешние;
- внутренние;
- программные.
Внешние (аппаратные)
прерывания
могут возникать в результате действий пользователя или оператора за терминалом
или же в результате поступления сигналов от аппаратных устройств – сигналов
завершения операций ввода-вывода, вырабатываемых контроллерами внешних
устройств компьютера, такими, как принтер или накопитель на жестких дисках,
или же сигналов от датчиков управляемых компьютером технических объектов.
Внешние прерывания называют также аппаратными, отражая тот факт, что прерывание
возникает вследствие подачи некоторой аппаратурой (например, контроллером
принтера) электрического сигнала, который передается (возможно, проходя через
другие блоки компьютера, например контроллер прерываний) на специальный вход
прерывания процессора. Данный класс прерываний является асинхронным по
отношению к потоку инструкций прерываемой программы. Аппаратура процессора
работает так, что асинхронные прерывания возникают между выполнением двух
соседних инструкций, при этом система после обработки прерывания продолжает
выполнение процесса уже начиная со следующей инструкции.
Внутренние прерывания, называемые также исключениями
(exception), происходят синхронно выполнению программы при появлении аварийной
ситуации в ходе исполнения некоторой инструкции программы. Примерами исключений
являются деление на нуль, ошибки защиты памяти, обращения по несуществующему
адресу, попытка выполнить привилегированную инструкцию в пользовательском
режиме и т. п. Исключения возникают непосредственно в ходе выполнения тактов
команды (“внутри” выполнения).
Программные прерывания отличаются от
предыдущих двух классов тем, что они по своей сути не являются “истинными”
прерываниями. Программное прерывание возникает при выполнении особой команды
процессора, выполнение которой имитирует прерывание, т.е. переход на новую
последовательность инструкций. Причины использования программных прерываний
вместо обычных инструкций вызова процедур будут изложены ниже, после
рассмотрения механизма прерываний.
Прерываниям приписывается
приоритет, с помощью которого они ранжируются по степени важности и срочности.
О прерываниях, имеющих одинаковое значение приоритета, говорят, что они
относятся к одному уровню приоритета прерываний.
Прерывания обычно
обрабатываются модулями операционной системы, так как действия, выполняемые по
прерыванию, относятся к управлению разделяемыми ресурсами вычислительной
системы – принтером, диском, таймером, процессором и т. п. Процедуры,
вызываемые по прерываниям, обычно называют обработчиками прерываний, или
процедурами обслуживания прерываний (Interrupt Service Routine, ISR).
Аппаратные прерывания обрабатываются драйверами соответствующих внешних
устройств, исключения – специальными модулями ядра, а программные прерывания –
процедурами ОС, обслуживающими системные вызовы. Кроме этих модулей, в
операционной системе может находиться так называемый диспетчер прерываний,
который координирует работу отдельных обработчиков прерываний.
Механизм
прерываний
Механизм прерываний
поддерживается аппаратными средствами компьютера и программными средствами
операционной системы.
Существуют
два основных способа, с помощью которых шины выполняют прерывания: векторный
(vectored) и опрашиваемый (polled). В обоих способах процессору
предоставляется информация об уровне приоритета прерывания на шине подключения
внешних устройств. В случае векторных прерываний в процессор передается также
информация о начальном адресе программы обработки возникшего прерывания –
обработчика прерываний.
Устройствам,
которые используют векторные прерывания, назначается вектор прерываний.
Он представляет собой электрический сигнал, выставляемый на соответствующие
шины процессора и несущий в себе информацию об определенном, закрепленном за
данным устройством номере, который идентифицирует соответствующий обработчик
прерываний. Этот вектор может быть фиксированным, конфигурируемым (например, с
использованием переключателей) или программируемым. Операционная система может
предусматривать процедуру регистрации вектора обработки прерываний для
определенного устройства, которая связывает некоторую подпрограмму обработки
прерываний с определенным вектором. При получении сигнала запроса прерывания
процессор выполняет специальный цикл подтверждения прерывания, в котором
устройство должно идентифицировать себя. В течение этого цикла устройство
отвечает, выставляя на шину вектор прерываний. Затем процессор использует этот
вектор для нахождения обработчика данного прерывания. Примером шины
подключения внешних устройств, которая поддерживает векторные прерывания,
является шина VMEbus.
При
использовании опрашиваемых прерываний процессор получает от запросившего
прерывание устройства только информацию об уровне приоритета прерывания
(например, номере IRQ на шине ISA или номере IPL на шине SBus компьютеров
SPARC). С каждым уровнем прерываний может быть связано несколько устройств и
соответственно несколько программ – обработчиков прерываний. При возникновении
прерывания процессор должен определить, какое устройство из тех, которые
связаны с данным уровнем прерываний, действительно запросило прерывание. Это
достигается вызовом всех обработчиков прерываний для данного уровня приоритета,
пока один из обработчиков не подтвердит, что прерывание пришло от
обслуживаемого им устройства. Если же с каждым уровнем прерываний связано
только одно устройство, то определение нужной программы обработки прерывания
происходит немедленно, как и при векторном прерывании. Опрашиваемые прерывания
поддерживают шины ISA, EISA, MCA, PCI и Sous.
Механизм
прерываний некоторой аппаратной платформы может сочетать векторный и
опрашиваемый типы прерываний. Типичным примером такой реализации является
платформа персональных компьютеров на основе процессоров Intel Pentium. Шины
PCI, ISA, EISA или MCA, используемые в этой платформе в качестве шин
подключения внешних устройств, поддерживают механизм опрашиваемых прерываний.
Контроллеры периферийных устройств выставляют на шину не вектор, а сигнал
запроса прерывания определенного уровня IRQ. Однако в процессоре Pentium
система прерываний является векторной. Вектор прерываний в процессор Pentium
поставляет контроллер прерываний, который отображает поступающий от шины
сигнал IRQ на определенный номер вектора. Вектор прерываний, передаваемый в
процессор, представляет собой целое число в диапазоне от 0 до 255, указывающее
на одну из 256 программ обработки прерываний, адреса которых хранятся в
таблице обработчиков прерываний. В том случае, когда к каждой линии IRQ
подключается только одно устройство, процедура обработки прерываний работает
так, как если бы система прерываний была чисто векторной, т.е. процедура не
выполняет никаких дополнительных опросов для выяснения того, какое именно
устройство запросило прерывание. Однако при совместном использовании одного
уровня IRQ несколькими устройствами программа обработки прерываний должна
работать в соответствии со схемой опрашиваемых прерываний, т.е. дополнительно
выполнить опрос всех устройств, подключенных к данному уровню IRQ.
Механизм прерываний чаще
всего поддерживает приоритезацию и маскирование прерываний.
Приоритезация означает, что все источники прерываний делятся на классы и
каждому классу назначается свой уровень приоритета запроса на прерывание.
Приоритеты могут обслуживаться как относительные и абсолютные. Обслуживание
запросов прерываний по схеме с относительными приоритетами заключается в том,
что при одновременном поступлении запросов прерываний из разных классов
выбирается запрос, имеющий высший приоритет. Однако в дальнейшем при
обслуживании этого запроса процедура обработки прерывания уже не откладывается
даже в том случае, когда появляются более приоритетные запросы – решение о
выборе нового запроса принимается только в момент завершения обслуживания
очередного прерывания. Если же более приоритетным прерываниям разрешается
приостанавливать работу процедур обслуживания менее приоритетных прерываний,
то это означает, что работает схема приоритезации с абсолютными приоритетами.
Если процессор (или компьютер, когда поддержка приоритезации прерываний
вынесена во внешний по отношению к процессору блок) работает по схеме с абсолютными
приоритетами, то он поддерживает в одном из своих внутренних регистров
переменную, фиксирующую уровень приоритета обслуживаемого в данный момент
прерывания. При поступлении запроса из определенного класса его приоритет
сравнивается с текущим приоритетом процессора, и если приоритет запроса выше,
то текущая процедура обработки прерываний вытесняется, а по завершении
обслуживания нового прерывания происходит возврат к прерванной процедуре.
Упорядоченное
обслуживание запросов прерываний наряду со схемами приоритетной обработки
запросов может выполняться механизмом маскирования запросов. Собственно
говоря, в описанной схеме абсолютных приоритетов выполняется маскирование –
при обслуживании некоторого запроса все запросы с равным или более низким
приоритетом маскируются, т.е. не обслуживаются. Схема маскирования предполагает
возможность временного маскирования прерываний любого класса независимо от
уровня приоритета.
Обобщенно
последовательность действий аппаратных и
программных средств по обработке прерывания можно описать следующим образом:
1. При возникновении сигнала (для аппаратных
прерываний) или условия (для внутренних прерываний) прерывания происходит
первичное аппаратное распознавание типа прерывания. Если прерывания данного
типа в настоящий момент запрещены (приоритетной схемой или механизмом
маскирования), то процессор продолжает поддерживать естественный ход выполнения
команд. В противном случае в зависимости от поступившей в процессор информации
(уровень прерывания, вектор прерывания или тип условия внутреннего прерывания)
происходит автоматический вызов процедуры обработки прерывания, адрес которой
находится в специальной таблице операционной системы, размещаемой либо в
регистрах процессора, либо в определенном месте оперативной памяти.
2. Автоматически сохраняется некоторая часть контекста
прерванного потока, которая позволит ядру возобновить исполнение потока
процесса после обработки прерывания. В это подмножество обычно включаются
значения счетчика команд, слова состояния машины, хранящего признаки основных
режимов работы процессора (пример такого слова – регистр EFLAGS в Intel
Pentium), а также нескольких регистров общего назначения, которые требуются программе
обработки прерывания. Может быть сохранен и полный контекст процесса, если ОС
обслуживает данное прерывание со сменой процесса. Однако в общем случае это не
обязательно, часто обработка прерываний выполняется без вытеснения текущего
процесса. Решение о перепланировании процессов может быть принято в ходе
обработки прерывания, например, если это прерывание от таймера, и после
наращивания значения системных часов выясняется, что процесс исчерпал
выделенный ему квант времени. Однако это совсем не обязательно – прерывание
может выполняться и без смены процесса, например прием очередной порции данных
от контроллера внешнего устройства чаще всего происходит в рамках текущего
процесса, хотя данные, скорее всего, предназначены другому процессу.
3. Одновременно с загрузкой адреса процедуры обработки
прерываний в счетчик команд может автоматически выполняться загрузка нового
значения слова состояния машины (или другой системной структуры, например
селектора кодового сегмента в процессоре Pentium), которое определяет режимы
работы процессора при обработке прерывания, в том числе работу в привилегированном
режиме.
4. Временно запрещаются прерывания данного типа, чтобы
не образовалась очередь вложенных друг в друга потоков одной и той же
процедуры. Детали выполнения этой операции зависят от особенностей аппаратной
платформы, например может использоваться механизм маскирования прерываний.
5. После того как прерывание обработано ядром
операционной системы, прерванный контекст восстанавливается и работа потока
возобновляется с прерванного места. Часть контекста восстанавливается
аппаратно по команде возврата из прерываний (например, адрес следующей команды
и слово состояния машины), а часть – программным способом, с помощью явных команд
извлечения данных из стека. При возврате из прерывания блокировка повторных
прерываний данного типа снимается.
20
СИНХРОНИЗАЦИЯ ПРОЦЕССОВ И ПОТОКОВ
Цель
синхронизации
Существует достаточно
обширный класс средств операционной системы, с помощью которых обеспечивается
взаимная синхронизация процессов и потоков1 . Потребность в
синхронизации потоков возникает только в мультипрограммной операционной системе
и связана с совместным использованием аппаратных и информационных ресурсов
вычислительной системы. Синхронизация необходима для исключения гонок и
тупиков при обмене данными между потоками, разделении данных, при доступе к
процессору и устройствам ввода-вывода.
Во многих операционных
системах эти средства называются средствами межпроцессного взаимодействия –
Inter Process Communications (IPC), что отражает историческую первичность
понятия “процесс” по отношению к понятию “поток”. Обычно к средствам IPC
относят не только средства межпроцессной синхронизации, но и средства
межпроцессного обмена данными.
Таким образом, потоки в
общем случае (когда программист не предпринял специальных мер по их
синхронизации) протекают независимо, асинхронно друг другу. Это справедливо как
по отношению к потокам одного процесса, выполняющим общий программный код, так
и по отношению к потокам разных процессов, каждый из которых выполняет
собственную программу.
Любое
взаимодействие процессов или потоков связано с их синхронизацией, которая
заключается в согласовании их скоростей путем приостановки потока до
наступления некоторого события и последующей его активизации при наступлении
этого события. Синхронизация лежит в основе любого взаимодействия потоков,
связано ли это взаимодействие с разделением ресурсов или с обменом данными.
Например, поток-получатель должен обращаться за данными только после того, как
они помещены в буфер потоком-отправителем. Если же поток-получатель обратился к
данным до момента их поступления в буфер, то он должен быть приостановлен.
Для
синхронизации потоков прикладных программ программист может использовать как
собственные средства и приемы синхронизации, так и средства операционной
системы. Обычно разработчики операционных систем предоставляют в распоряжение
прикладных и системных программистов широкий спектр средств синхронизации. Эти
средства могут образовывать иерархию, когда на основе более простых средств
строятся более сложные, а также быть функционально специализированными,
например средства для синхронизации потоков одного процесса, средства для
синхронизации потоков разных процессов при обмене данными и т.д. Часто
функциональные возможности разных системных вызовов синхронизации перекрываются,
так что для решения одной задачи программист может воспользоваться несколькими
вызовами в зависимости от своих личных предпочтений.
Средства синхронизации
Важным понятием
синхронизации потоков является понятие “критической секции” программы. Критическая
секция – это часть программы, результат выполнения которой может
непредсказуемо меняться, если переменные, относящиеся к этой части программы,
изменяются другими потоками в то время, когда выполнение этой части еще не
завершено. Критическая секция всегда определяется по отношению к определенным
критическим данным, при несогласованном изменении которых могут возникнуть
нежелательные эффекты
Чтобы исключить эффект
гонок по отношению к критическим данным, необходимо обеспечить, чтобы в каждый
момент времени в критической секции, связанной с этими данными, находился
только один поток. При этом неважно, находится этот поток в активном или в
приостановленном состоянии. Этот прием называют взаимным исключением.
Операционная система использует разные способы реализации взаимного исключения.
Некоторые способы пригодны для взаимного исключения при вхождении в критическую
секцию только потоков одного процесса, в то время как другие могут обеспечить
взаимное исключение для потоков разных процессов.
Самый простой и в то же
время неэффективный способ обеспечения взаимного исключения состоит в том, что
операционная система позволяет потоку запрещать любые прерывания на время его
нахождения в критической секции. Однако этот способ практически не применяется,
поскольку опасно доверять управление системой пользовательскому процессу – он
может надолго занять процессор, а при крахе потока в критической секции крах
потерпит вся система, потому что прерывания никогда не будут разрешены.
Для синхронизации
потоков одного процесса программист может использовать глобальные блокирующие
переменные. С этими переменными, к которым все потоки процесса имеют прямой
доступ, программист работает, не обращаясь к системным вызовам ОС. Каждому
набору критических данных ставится в соответствие двоичная переменная, которой
поток присваивает значение 0, когда он входит в критическую секцию, и значение
1, когда он ее покидает.
Блокирующие
переменные могут использоваться не только при доступе к разделяемым данным, но
и при доступе к разделяемым ресурсам любого вида.
Если
все потоки написаны с учетом вышеописанных соглашений, то взаимное исключение
гарантируется. При этом потоки могут быть прерваны операционной системой в
любой момент и в любом месте, в том числе в критической секции.
Реализация
взаимного исключения описанным выше способом имеет существенный недостаток: в
течение времени, когда один поток находится в критической секции, другой поток,
которому требуется тот же ресурс, получив доступ к процессору, будет
непрерывно опрашивать блокирующую переменную, бесполезно тратя выделяемое ему
процессорное время, которое могло бы быть использовано для выполнения какого-нибудь
другого потока. Для устранения этого недостатка во многих ОС предусматриваются
специальные системные вызовы для работы с критическими секциями.
Обобщением
блокирующих переменных являются так называемые семафоры Дийкстры. Вместо
двоичных переменных Дийкстра (Dijkstra) предложил использовать переменные,
которые могут принимать целые неотрицательные значения. Такие переменные,
используемые для синхронизации вычислительных процессов, получили название
семафоров.
Для
работы с семафорами вводятся два примитива, традиционно обозначаемых Р и V.
Пусть переменная S представляет собой семафор. Тогда действия V(S) и P(S)
определяются следующим образом:
- V(S): переменная S увеличивается на 1 единым
действием. Выборка, наращивание и запоминание не могут быть прерваны. К
переменной S нет доступа другим потокам во время выполнения этой операции.
- P(S): уменьшение S на 1, если это возможно. Если S=0
и невозможно уменьшить S, оставаясь в области целых неотрицательных значений,
то в этом случае поток, вызывающий операцию Р, ждет, пока это уменьшение станет
возможным. Успешная проверка и уменьшение также являются неделимой операцией.
Никакие
прерывания во время выполнения примитивов V и Р недопустимы.
В
частном случае, когда семафор S может принимать только значения 0 и 1, он
превращается в блокирующую переменную, которую по этой причине часто называют
двоичным семафором. Операция Р заключает в себе потенциальную возможность
перехода потока, который ее выполняет, в состояние ожидания, в то время как
операция V может при некоторых обстоятельствах активизировать другой поток,
приостановленный операцией Р.
Таким
образом, семафоры позволяют эффективно решать задачу синхронизации доступа к
ресурсным пулам, таким, например, как набор идентичных в функциональном
назначении внешних устройств (модемов, принтеров, портов) или набор областей
памяти одинаковой величины, или информационных структур. Во всех этих и
подобных им случаях с помощью семафоров можно организовать доступ к разделяемым
ресурсам сразу нескольких потоков.
Семафор
может использоваться и в качестве блокирующей переменной.
Рассмотренные
выше механизмы синхронизации, основанные на использовании глобальных переменных
процесса, обладают существенным недостатком – они не подходят для синхронизации
потоков разных процессов. В таких случаях операционная система должна
предоставлять потокам системные объекты синхронизации, которые были бы видны
для всех потоков, даже если они принадлежат разным процессам и работают в
разных адресных пространствах.
Примерами
таких синхронизирующих объектов ОС являются системные семафоры, мьютексы,
события, таймеры и другие – их набор зависит от конкретной ОС, которая
создает эти объекты по запросам процессов. Чтобы процессы могли разделять
синхронизирующие объекты, в разных ОС используются разные методы. Некоторые ОС
возвращают указатель на объект. Этот указатель может быть доступен всем
родственным процессам, наследующим характеристики общего родительского
процесса. В других ОС процессы в запросах на создание объектов синхронизации
указывают имена, которые должны быть им присвоены. Далее эти имена используются
разными процессами для манипуляций объектами синхронизации. В таком случае
работа с синхронизирующими объектами подобна работе с файлами. Их можно
создавать, открывать, закрывать, уничтожать.
Кроме
того, для синхронизации могут быть использованы такие “обычные” объекты ОС,
как файлы, процессы и потоки. Все эти объекты могут находиться в двух
состояниях: сигнальном и несигнальном – свободном. Для каждого объекта смысл,
вкладываемый в понятие “сигнальное состояние”, зависит от типа объекта. Так,
например, поток переходит в сигнальное состояние тогда, когда он завершается.
Процесс переходит в сигнальное состояние тогда, когда завершаются все его
потоки. Файл переходит в сигнальное состояние в том случае, когда завершается
операция ввода-вывода для этого файла. Для остальных объектов сигнальное
состояние устанавливается в результате выполнения специальных системных вызовов.
Приостановка и активизация потоков осуществляются в зависимости от состояния
синхронизирующих объектов ОС.
Потоки
с помощью специального системного вызова сообщают операционной системе о том,
что они хотят синхронизировать свое выполнение с состоянием некоторого
объекта. Будем далее называть этот системный вызов Wait(X), где Х – указатель
на объект синхронизации. Системный вызов, с помощью которого поток может
перевести объект синхронизации в сигнальное состояние, назовем Set(X).
Поток,
выполнивший системный вызов Wait(X), переводится операционной системой в
состояние ожидания до тех пор, пока объект Х не перейдет в сигнальное
состояние. Примерами системных вызовов типа Wait() и Set() являются вызовы
MaitForSingleObject() и SetEvent() в Windows NT, DosSemWait() и DosSemSet() в
OS/2, s1eep() и wakeup() в UNIX.
Поток
может ожидать установки сигнального состояния не одного объекта, а нескольких.
При этом поток может попросить ОС активизировать его при установке либо одного
из указанных объектов, либо всех объектов. Поток может в качестве аргумента
системного вызова Wait() указать также максимальное время, которое он будет
ожидать перехода объекта в сигнальное состояние, после чего ОС должна его
активизировать в любом случае. Может случиться, что установки некоторого
объекта в сигнальное состояние ожидают сразу несколько потоков. В зависимости
от объекта синхронизации в состояние готовности могут переводиться либо все
ожидающие это событие потоки, либо один из них.
Синхронизация тесно
связана с планированием потоков. Во-первых, любое обращение потока с системным
вызовом Wait(X) влечет за собой действия в подсистеме планирования – этот
поток снимается с выполнения и помещается в очередь ожидающих потоков, а из
очереди готовых потоков выбирается и активизируется новый поток. Во-вторых,
при переходе объекта в сигнальное состояние (в результате выполнения
некоторого потока – либо системного, либо прикладного) ожидающий этот объект
поток (или потоки) переводится в очередьготовых к выполнению потоков. В обоих
случаях осуществляется перепланирование потоков, при этом если в ОС
предусмотрены изменяемые приоритеты и/или кванты времени, то они
пересчитываются по правилам, принятым в этой операционной системе.
22,23 Управление памятью
Задачи
операционной системы по управлению памятью
Память является важнейшим ресурсом, требующим тщательного управления со
стороны мультипрограммной операционной системы (ОС). Особая роль памяти объясняется
тем, что процессор может выполнять инструкции программы только в том случае,
если они находятся в памяти. Память распределяется как между модулями
прикладных программ, так и между модулями самой операционной системы.
С появлением мультипрограммирования перед ОС были поставлены новые
задачи, связанные с распределением имеющейся памяти между несколькими
одновременно выполняющимися программами.
Функции ОС по управлению памятью в
мультипрограммной системе следующие:
отслеживание
свободной и занятой памяти;
выделение
памяти процессам и освобождение памяти по завершении процессов;
вытеснение
кодов и данных процессов из оперативной памяти на диск (полное или частичное),
когда размеры основной памяти не достаточны для размещения в ней всех
процессов, и возвращение их в оперативную память, когда в ней освобождается
место; настройка
адресов программы на конкретную область физической памяти.
Помимо первоначального выделения памяти процессам при их создании ОС
должна также заниматься динамическим распределением памяти, т.е. выполнять
запросы приложений на выделение им дополнительной памяти во время выполнения.
После того как приложение перестает нуждаться в дополнительной памяти, оно
может возвратить ее системе.
Защита памяти – это еще одна важная задача операционной системы,
которая состоит в том, чтобы не позволить выполняемому процессу записывать или
читать данные из памяти, назначенной другому процессу. Эта функция, как правило,
реализуется программными модулями ОС в тесном взаимодействии с аппаратными
средствами.
Типы адресов
Для идентификации переменных и команд на разных этапах жизненного цикла
программы используются символьные имена (метки), виртуальные адреса и физические
адреса (рис. 1).
Символьные имена
присваивает пользователь при написании программы на алгоритмическом языке или
ассемблере.
Виртуальные адреса,
называемые иногда математическими, или логическими адресами,
вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во
время трансляции в общем случае не известно, в какое место оперативной памяти
будет загружена программа, то транслятор присваивает переменным и командам
виртуальные (условные) адреса, обычно считая по умолчанию, что начальным
адресом программы будет нулевой адрес.
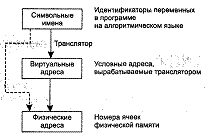 Физические адреса
соответствуют номерам ячеек оперативной памяти, где в действительности
расположены или будут расположены переменные и команды.
Физические адреса
соответствуют номерам ячеек оперативной памяти, где в действительности
расположены или будут расположены переменные и команды.
Рис.
1. Типы адресов
Совокупность виртуальных адресов процесса называется виртуальным
адресным пространством. Диапазон возможных адресов виртуального
пространства у всех процессов является одним и тем же. Например, при
использовании 32-разрядных виртуальных адресов этот диапазон задается границами
0000000016 и FFFFFFFF16. Совпадение виртуальных адресов переменных и команд
различных процессов не приводит к конфликтам, так как в том случае, когда эти
переменные одновременно присутствуют в памяти, операционная система отображает
их на разные физические адреса.
В разных операционных системах используются разные
способы структуризации виртуального адресного пространства. В одних ОС
виртуальное адресное пространство процесса подобно физическойпамяти
представлено в виде непрерывной линейной последовательности виртуальных
адресов. Такую структуру адресного пространства называют также плоской (flat).
При этом виртуальным адресом является единственное число, представляющее собой
смещение относительно начала (обычно это значение 000…000) виртуального
адресного пространства . Адрес такого типа называют линейным виртуальным адресом
В других ОС виртуальное адресное пространство делится на части, называемые
сегментами (или секциями, или областями, или другими терминами). В этом случае
помимо линейного адреса может быть использован виртуальный адрес,
представляющий собой пару чисел (n, m), где n определяет сегмент, а m – смещение
внутри сегмента.
Существуют и более сложные способы структуризации виртуального
адресного пространства, когда виртуальный адрес образуется тремя или даже более
числами.Задачей операционной системы является отображение индивидуальных виртуальных
адресных пространств всех одновременно выполняющихся процессов на общую
физическую память. При этом ОС отображает либо все виртуальное адресное
пространство, либо только определенную его часть.
Существуют два принципиально отличающихся подхода к преобразованию виртуальных адресов в физические.
В первом случае замена виртуальных адресов на физические выполняется
один раз для каждого процесса во время начальной загрузки программы в память.
Специальная системная программа – перемещающий загрузчик – на
основании имеющихся у нее исходных данных о начальном адресе физической памяти,
в которую предстоит загружать программу, а также информации, предоставленной
транслятором об адресно-зависимых элементах программы, выполняет загрузку
программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в
неизмененном виде в виртуальных адресах, т. е. операнды инструкций и адреса
переходов имеют те значения, которые выработал транслятор.
Максимальный размер виртуального адресного пространства ограничивается
только разрядностью адреса, присущей данной архитектуре компьютера, и, как правило,
не совпадает с объемом физической памяти, имеющимся в компьютере.
Сегодня для машин универсального назначения типична ситуация, когда
объем виртуального адресного пространства превышает доступный объем оперативной
памяти. В таком случае операционная система для хранения данных виртуального
адресного пространства процесса, не помещающихся в оперативную память, использует
внешнюю память, которая в современных компьютерах представлена жесткими дисками
. Именно на этом принципе основана виртуальная память – наиболее
совершенный механизм, используемый в операционных системах для управления
памятью.
Обычно виртуальное адресное пространство процесса делится на две
непрерывные части: системную и пользовательскую. В некоторых ОС (например, Windows
NT, OS/2) эти части имеют одинаковый размер – по 2 Гбайт,. Часть виртуального
адресного пространства каждого процесса, отводимая под сегменты ОС, является
идентичной для всех процессов.
Алгоритмы распределения памяти
Все алгоритмы распределения памяти можно разделить на два класса (рис.
6): алгоритмы, в которых используется перемещение сегментов процессов между
оперативной памятью и диском, и алгоритмы, в которых внешняя память не
привлекается. Рис. 6. Классификация методов распределения памяти
Рис. 6. Классификация методов распределения памяти
Одиночное непрерывное
распределение памяти
Одиночное непрерывное распределение – это самая простая схема, согласно которой вся
память условно может быть разделена на три части:1) область, занимаемая
операционной системой;2) область, в которой размещается исполняемая задача;3)
незанятая ничем (свободная) область памяти.Программные модули, необходимые для
всех программ, располагаются в области самой ОС, а вся оставшаяся память может
быть предоставлена задаче. Чтобы для задач отвести как можно больший объем
памяти, операционная система строится таким образом, что постоянно в
оперативной памяти располагается только самая нужная ее часть. Эту часть ОС стали называть ядром. Остальные
модули ОС могут быть обычными диск-резидентными (или транзитными), т. е.
загружаться в оперативную память только по необходимости и после своего
выполнения вновь освобождать памятьТакая схема распределения влечет за собой
два вида потерь вычислительных ресурсов – потеря процессорного времени, потому
что процессор простаивает, пока задача ожидает завершения операций
ввода/вывода, и потеря самой оперативной памяти, потому что далеко не каждая
программа использует всю память, а режим работы в этом случае однопрограммный.
Схема одиночного непрерывного распределения памяти характерна для MS-DOS.
Распределение памяти разделами с фиксированными границами
Простейший способ управления оперативной памятью состоит в том, что
память разбивается на несколько областей фиксированной величины, называемых разделами.
Такое разбиение может быть выполнено вручную оператором во время старта системы
или во время ее установки. После этого границы разделов не изменяются.
 Очередной новый процесс, поступивший на выполнение,
помещается либо в общую очередь (рис. 7, а), либо в очередь к
некоторому разделу (рис. 7, б).Рис.
7. Распределение памяти фиксированными разделами: а) с общей
очередью; б) с отдельными очередями
Очередной новый процесс, поступивший на выполнение,
помещается либо в общую очередь (рис. 7, а), либо в очередь к
некоторому разделу (рис. 7, б).Рис.
7. Распределение памяти фиксированными разделами: а) с общей
очередью; б) с отдельными очередями
Подсистема управления памятью в этом случае выполняет следующие задачи: сравнивает объем памяти, требуемый
для вновь поступившего процесса, с размерами свободных разделов и выбирает
подходящий раздел;
осуществляет
загрузку программы в один из разделов и настройку адресов. Уже на этапе
трансляции разработчик программы может задать раздел, в котором ее следует
выполнять. Это позволяет сразу, без использования перемещающего загрузчика,
получить машинный код, настроенный на конкретную область памяти.При очевидном
преимуществе – простоте реализации, данный метод имеет существенный недостаток
– жесткость. Так как в каждом разделе может выполняться только один процесс,
то уровень мультипрограммирования заранее ограничен числом разделов.
Независимо от размера программы она будет занимать весь раздел. Такой способ
управления памятью применялся в ранних мультипрограммных ОС. Однако и сейчас
метод распределения памяти фиксированными разделами находит применение в
системах реального времени, в основном благодаря небольшим затратам на
реализацию
Распределение памяти разделами с динамическими границами
. Сначала вся память, отводимая для приложений, свободна. Каждому
вновь поступающему на выполнение приложению на этапе создания процесса
выделяется вся необходимая ему память (если достаточный объем памяти
отсутствует, то приложение не принимается на выполнение и процесс для него не
создается). После завершения процесса память освобождается, и на это место
может быть загружен другой процесс.
Перечислим функции операционной системы, предназначенные для реализации
данного метода управления памятью.
Ведение
таблиц свободных и занятых областей, в которых указываются начальные адреса и
размеры участков памяти.
При
создании нового процесса – анализ требований к памяти, просмотр таблицы
свободных областей и выбор раздела, размер которого достаточен для размещения
кодов и данных нового процесса. Выбор раздела может осуществляться по разным
правилам, например “первый попавшийся раздел достаточного размера”, “раздел,
имеющий наименьший достаточный размер” или “раздел, имеющий наибольший
достаточный размер”.
Загрузка
программы в выделенный ей раздел и корректировка таблиц свободных и занятых
областей. Данный способ предполагает, что программный код не перемещается во
время выполнения, а значит настройка адресов может быть проведена
единовременно во время загрузки.
После
завершения процесса – корректировка таблиц свободных и занятых областей.
По сравнению с методом распределения памяти фиксированными разделами
данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный
недостаток – фрагментация памяти. Распределение памяти динамическими разделами
лежит в основе подсистем управления памятью многих мультипрограммных
операционных системах 60-70-х годов, в частности такой популярной операционной
системы, как OS/360.
Распределение памяти подвижными
разделами
Одним из методов борьбы с фрагментацией является перемещение всех
занятых участков в сторону старших или младших адресов, так, чтобы вся
свободная память образовала единую свободную область . В дополнение к функциям,
которые выполняет ОС при распределении памяти динамическими разделами, в
данном случае она должна еще время от времени копировать содержимое разделов из
одного места памяти в другое, корректируя таблицы свободных и занятых
областей. Эта процедура называется сжатием. Сжатие может выполняться
либо при каждом завершении процесса, либо только тогда, когда для вновь
создаваемого процесса нет свободного раздела достаточного размера. В первом
случае требуется меньше вычислительной работы при корректировке таблиц
свободных и занятых областей, а во втором – реже выполняется процедура сжатия.
Хотя процедура сжатия и приводит к более эффективному
использованию памяти, она может потребовать значительного времени, что часто
перевешивает преимущества данного метода. Такой подход был использован в
ранних версиях OS/2.
24,25
Свопинг и виртуальная память
Понятие свопинга
Виртуальным называется ресурс, который пользователю или
пользовательской программе представляется обладающим свойствами, которыми он в
действительности не обладает. Виртуализация оперативной памяти осуществляется
совокупностью программных модулей ОС и аппаратных схем процессора и включает
решение следующих задач:
размещение
данных в запоминающих устройствах разного типа, например часть кодов программы
– в оперативной памяти, а часть – на диске;
выбор
образов процессов или их частей для перемещения из оперативной памяти на диск
и обратно;
перемещение
по мере необходимости данных между памятью и диском;
преобразование
виртуальных адресов в физические.
Виртуализация памяти может быть
осуществлена на основе двух различных подходов:
свопинг
(swapping) – образы процессов выгружаются на диск и возвращаются в
оперативную память целиком;
виртуальная
память (virtual memory) – между оперативной памятью и диском перемещаются
части (сегменты, страницы и т. п.) образов процессов.
Свопинг представляет собой частный случай виртуальной памяти и, следовательно, более
простой в реализации способ совместного использования оперативной памяти и
диска. Однако подкачке свойственна избыточность: когда ОС решает
активизировать процесс, для его выполнения, как правило, не требуется загружать
в оперативную память все его сегменты полностью – достаточно загрузить
небольшую часть кодового сегмента с подлежащей выполнению инструкцией и частью
сегментов данных, с которыми работает эта инструкция, а также отвести место
под сегмент стекаПеремещение избыточной информации замедляет работу системы, а
также приводит к неэффективному использованию памяти. Кроме того, системы,
поддерживающие свопинг, имеют еще один очень существенный недостаток: они не
способны загрузить для выполнения процесс, виртуальное адресное пространство
которого превышает имеющуюся в наличии свободную память.
Именно из-за указанных недостатков свопинг как основной механизм
управления памятью почти не используется в современных OC.
Ключевой проблемой виртуальной памяти, возникающей в результате многократного
изменения местоположения в оперативной памяти образов процессов или их частей,
является преобразование виртуальных адресов в физические. Решение этой
проблемы, в свою очередь, зависит от того, какой способ структуризации
виртуального адресного пространства принят в данной системе управления
памятью. В настоящее время все множество реализации виртуальной памяти может
быть представлено тремя классами:
Страничная
виртуальная память организует перемещение данных между памятью и диском
страницами – частями виртуального адресного пространства, фиксированного и
сравнительно небольшого размера.
Сегментная
виртуальная память предусматривает перемещение данных сегментами – частями
виртуального адресного пространства произвольного размера, полученными с
учетом смыслового значения данных.
Сегментно-страничная виртуальная память использует
двухуровневое деление: виртуальное адресное пространство делится на сегменты,
а затем сегменты делятся на страницы. Единицей перемещения данных здесь
является страница. Этот способ управления памятью объединяет в себе элементы
обоих предыдущих подходов.
Страничное распределение памяти
Виртуальное адресное
пространство каждого процесса делится на части одинакового, фиксированного для
данной системы размера, называемые виртуальными страницами (virtual pages). В
общем случае размер виртуального адресного пространства процесса не кратен
размеру страницы, поэтому последняя страница каждого процесса дополняется
фиктивной областью.
Вся оперативная память машины также делится на части такого же размера,
называемые физическими страницами (или блоками, или кадрами).
Размер страницы выбирается равным степени двойки: 512, 1024, 4096 байт и т. д.
Это позволяет упростить механизм преобразования адресов.
При создании процесса ОС загружает в оперативную память несколько его
виртуальных страниц (начальные страницы кодового сегмента и сегмента данных).
Копия всего виртуального адресного пространства процесса находится на диске.
Для каждого процесса операционная система создает таблицу страниц –
информационную структуру, содержащую записи обо всех виртуальных страницах
процесса
Запись таблицы, называемая дескриптором страницы,
включает следующую информацию:
номер
физической страницы, в которую загружена данная виртуальная страница;
признак
присутствия, устанавливаемый в единицу, если виртуальная страница
находится в оперативной памяти;
признак
модификации страницы, который устанавливается в единицу всякий раз,
когда производится запись по адресу, относящемуся к данной странице;
признак
обращения к странице, называемый также битом доступа,
который устанавливается в единицу при каждом обращении по адресу, относящемуся
к данной странице.
Информация из таблиц страниц используется для решения вопроса о
необходимости перемещения той или иной страницы между памятью и диском, а
также для преобразования виртуального адреса в физический. Сами таблицы
страниц, так же как и описываемые ими страницы, размещаются в оперативной
памяти. Адрес таблицы страниц включается в контекст соответствующего процесса.
При активизации очередного процесса операционная система загружает адрес его
таблицы страниц в специальный регистр процессора.
При каждом обращении к памяти выполняется поиск номера
виртуальной страницы, содержащей требуемый адрес, затем по этому номеру определяется
нужный элемент таблицы страниц, и из него извлекается описывающая страницу
информация. Далее анализируется признак присутствия, и, если данная виртуальная
страница находится в оперативной памяти,
выполняется преобразование виртуального адреса в физический, т. е.
виртуальный адрес заменяется указанным в записи таблицы физическим адресом.
Если же нужная виртуальная страница в данный момент выгружена на диск, то
происходит так называемое страничное прерывание. Выполняющийся
процесс переводится в состояние ожидания, и активизируется другой процесс из
очереди процессов, находящихся в состоянии готовности. Параллельно программа
обработки страничного прерывания находит на диске требуемую виртуальную
страницу (для этого операционнаясистема должна помнить положение вытесненной
страницы в страничном файле диска) и пытается загрузить ее в оперативную
память. Если в памяти имеется свободная физическая страница, то загрузка
выполняется немедленно, если же свободных страниц нет, то на основании принятой
в данной системе стратегии замещения страниц решается вопрос о том, какую
страницу следует выгрузить из оперативной памяти.
Виртуальный адрес при страничном распределении может быть представлен в
виде пары (р, sv), где р – порядковый номер виртуальной страницы
процесса (нумерация страниц начинается с 0), a sv –
смещение в пределах виртуальной страницы. Физический адрес также может быть
представлен в виде пары (n, sf), где n – номер физической страницы, а sf –
смещение в пределах физической страницы. Задача подсистемы виртуальной памяти
состоит в отображении (р, sv) в (n, sf).
Сегментное распределение памяти
Виртуальное адресное пространство процесса
делится на части – сегменты, размер которых определяется с учетом
смыслового значения содержащейся в них информации. Отдельный сегмент может
представлять собой подпрограмму, массив данных и т.п. Деление виртуального
адресного пространства на сегменты осуществляется компилятором на основе
указаний программиста или по умолчанию, в соответствии с принятыми в системе
соглашениями. Максимальный размер сегмента определяется разрядностью
виртуального адреса, например при 32-разрядной организации процессора он равен
4 Гбайт. При этом максимально возможное виртуальное адресное пространство
процесса представляет собой набор из N виртуальных сегментов, каждый размером
по 4 Гбайт. В каждом сегменте виртуальные адреса находятся в диапазоне от
0000000016 до FFFFFFFF16. Сегменты не упорядочиваются друг относительно друга,
так что общего для сегментов линейного виртуального адреса не существует,
виртуальный адрес задается парой чисел: номером сегмента и линейным
виртуальным адресом внутри сегмента.
При загрузке процесса в оперативную память помещается только часть его
сегментов, полная копия виртуального адресного пространства находится в дисковой
памяти. Для каждого загружаемого сегмента операционная система подыскивает
непрерывный участок свободной памяти достаточного размера. Смежные в
виртуальной памяти сегменты одного процесса могут занимать в оперативной памяти
несмежные участки. Если во время выполнения процесса происходит обращение по
виртуальному адресу, относящемуся к сегменту, который в данный момент
отсутствует в памяти, то происходит прерывание. ОС приостанавливает активный
процесс, запускает на выполнение следующий процесс из очереди, а параллельно
организует загрузку нужного сегмента с диска. При отсутствии в памяти места,
необходимого для загрузки сегмента, операционная система выбирает сегмент на
выгрузку, при этом она использует критерии, аналогичные рассмотренным выше
критериям выбора страниц при страничном способе управления памятью.
На этапе создания процесса во время загрузки его образа в оперативную
память система создает таблицу сегментов процесса (аналогичную
таблице страниц), в которой для каждого сегмента указывается:
базовый
физический адрес сегмента в оперативной памяти;
размер
сегмента;
правила
доступа к сегменту;
признаки
модификации, присутствия и обращения к данному сегменту, а также некоторая
другая информация.
Если виртуальные адресные пространства нескольких процессов включают
один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки
на один и тот же участок оперативной памяти, в который данный сегмент загружается
в единственном экземпляре.
Виртуальный адрес при сегментной организации памяти
может быть представлен парой (g, s), где g – номер сегмента, а s – смещение в
сегменте. Физический адрес получается путем сложения базового адреса сегмента,
который определяется по номеру сегмента g из таблицы сегментов, и смещения s .
Система с сегментной организацией функционирует аналогично системе со
страничной организацией: при каждом обращении к оперативной памяти выполняется
преобразование виртуального адреса в физический, время от времени происходят
прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости
освобождения памяти некоторые сегменты выгружаются.Одним из существенных
отличий сегментной организации памяти от страничной является возможность
задания дифференцированных прав доступа процесса к его сегментам.
Сегментно-страничное распределение памяти
Данный метод представляет собой комбинацию страничного и сегментного
механизмов управления памятью и направлен на реализацию достоинств обоих
подходов.
Так же как и при сегментной организации памяти, виртуальное адресное
пространство процесса разделено на сегменты. Это позволяет определять разные
права доступа к разным частям кодов и данных программы.
Перемещение данных между памятью и диском осуществляется не сегментами,
а страницами. Для этого каждый виртуальный сегмент и физическая память делятся
на страницы равного размера, что позволяет более эффективно использовать
память, сократив до минимума фрагментацию.
Координаты байта в виртуальном адресном пространстве при сегментно-страничной
организации можно задать двумя способами. Во-первых, линейным виртуальным
адресом, который равен сдвигу данного байта относительно границы общего линейного
виртуального пространства, во-вторых, парой чисел, одно из которых является
номером сегмента, а другое – смещением относительно начала сегмента. Системы
виртуальной памяти ОС с сегментно-страничной организацией используют второй
способ, так как он позволяет непосредственно определить принадлежность адреса
некоторому сегменту и проверить права доступа процесса к нему.
Для каждого процесса операционная система создает отдельную таблицу
сегментов, в которой содержатся описатели (дескрипторы) всех сегментов
процесса. Описание сегмента включает назначенные ему права доступа и другие
характеристики, подобные тем, которые содержатся в дескрипторах сегментов при
сегментной организации памяти.
Наличие базового виртуального адреса сегмента в дескрипторе позволяет
однозначно преобразовать адрес, заданный в виде пары (номер сегмента, смещение
в сегменте), в линейный виртуальный адрес байта, который затем преобразуется в
физический адрес страничным механизмом.
Деление общего линейного виртуального адресного пространства процесса и
физической памяти на страницы осуществляется так же, как это делается при страничной
организации памяти. Размер страниц выбирается равным степени двойки, что
упрощает механизм преобразования виртуальных адресов в физические. Виртуальные
страницы нумеруются в пределах виртуального адресного пространства каждого
процесса, а физические страницы – в пределах оперативной памяти. При создании
процесса в память загружается только часть страниц, остальные загружаются по
мере необходимости. Время от времени система выгружает уже ненужные страницы,
освобождая память для новых страниц. ОС ведет для каждого процесса таблицу
страниц, в которой указывается соответствие виртуальных страниц физическим.
26 Управление
файлами и устройствами
Задачи ОС по
управлению файлами и устройствами
В современной ОС функции обмена
данными с периферийными устройствами выполняет подсистема ввода-вывода. Основными
компонентами подсистемы ввода-вывода являются драйверы, управляющие внешними
устройствами, и файловая система.
Драйвер устройства – это многовходовой программный модуль со своими статическими данными,
который умеет инициировать работу с устройством, выполнять заказываемые
пользователем обмены (на ввод или вывод данных), терминировать работу с
устройством и обрабатывать прерывания от устройства.
Подсистема ввода-вывода (Input-Output Subsystem) мультипрограммной ОС
при обмене данными с внешними устройствами компьютера должна решать ряд общих
задач, из которых наиболее важными являются следующие:
организация
параллельной работы устройств ввода-вывода и процессора;
согласование
скоростей обмена и кэширование данных;
разделение
устройств и данных между процессами;
обеспечение
удобного логического интерфейса между устройствами и остальной частью системы;
поддержка
широкого спектра драйверов с возможностью простого включения в систему нового
драйвера;
динамическая
загрузка и выгрузка драйверов;
поддержка нескольких файловых систем;
поддержка
синхронных и асинхронных операций ввода-вывода.
Организация параллельной работы устройств ввода-вывода и процессора
Каждое устройство ввода-вывода
вычислительной системы – диск, принтер, терминал и т. п. – снабжено
специализированным блоком управления, называемым контроллером. Контроллер
взаимодействует с драйвером – системным программным модулем, предназначенным
для управления данным устройством. Контроллер периодически принимает от
драйвера выводимую на устройство информацию, а также команды управления,
которые говорят о том, что с этой информацией нужно сделать (например, вывести
в виде текста в определенную область терминала или записать в определенный
сектор диска). управлением контроллера устройство может некоторое время
выполнять свои операции автономно, не требуя внимания со стороны центрального
процессора. Это время зависит от многих факторов – объема выводимой
информации, степени интеллектуальности управляющего устройством контроллера,
быстродействия устройства и т.д..
Процессы, происходящие в контроллерах, протекают в периоды между
выдачами команд независимо от ОС. От подсистемы ввода-вывода требуется спланировать
в реальном масштабе времени (в котором работают внешние устройства) запуск и
приостановку большого количества разнообразных драйверов, обеспечив приемлемое
время реакции каждого драйвера на независимые события контроллераДанная задача
является классической задачей планирования систем реального времени и обычно
решается на основе многоуровневой приоритетной схемы обслуживания по
прерываниям. Для обеспечения приемлемого уровня реакции все драйверы (или части
драйверов) распределяются по нескольким приоритетным уровням в соответствии с
требованиями ко времени реакции и временем использования процессора. Для
реализации приоритетной схемы обычно задействуется общий диспетчер прерываний
ОС.
Согласование
скоростей обмена и кэширование данных
При обмене данными всегда возникает задача согласования скорости.
Например, если один пользовательский процесс вырабатывает некоторые данные и
передает их другому пользовательскому процессу через оперативную память, то в
общем случае скорости генерации данных и их чтения не совпадают. Согласование
скорости обычно достигается за счет буферизации данных в оперативной памяти и
синхронизации доступа процессов к буферу.
В подсистеме ввода-вывода для согласования скоростей обмена также
широко используется буферизация данных в оперативной памяти. Другим решением
этой проблемы является использование большой буферной памяти в контроллерах
внешних устройствБуферизация данных позволяет не только согласовать скорости
работы процессора и внешнего устройства, но и решить другую задачу – сократить
количество реальных операций ввода-вывода за счет кэширования данных. Дисковый
кэш является непременным атрибутом подсистем ввода-вывода практически всех операционных
систем, значительно сокращая время доступа к хранимым данным.
Разделение
устройств и данных между процессами
Устройства ввода-вывода могут предоставляться процессам как в
монопольное, так и в совместное (разделяемое) использование. При этом ОС должна
обеспечивать контроль доступа теми же способами, что и при доступе процессов к
другим ресурсам вычислительной системы – путем проверки прав пользователя или
группы пользователей, от имени которых действует процесс, на выполнение той или
иной операции над устройством. Например, определенной группе пользователей
последовательный порт разрешено захватывать в монопольное владение, а другим
пользователям это запрещено.
Операционная система может контролировать доступ не
только к устройству в целом, но и к отдельным порциям данных, хранимых или
отображаемых этим устройством. Диск является типичным примером устройства, для
которого важно контролировать доступ не к устройству в целом, а к отдельным
каталогам и файлам. При выводе информациина графический дисплей отдельные окна
экрана также представляют собой ресурсы, к которым необходимо обеспечить тот
или иной вид доступа для протекающих в системе процессов. При этом для каждой
порции данных или части устройства могут быть заданы свои права доступа, не
связанные прямо с правами доступа к устройству в целом. Так, в файловой системе
обычно для каждого каталога и файла можно задать индивидуальные права доступа.
Одно и то же устройство в разные периоды времени может использоваться
как в разделяемом, так и в монопольном режимах. Тем не менее, существуют
устройства, для которых обычно характерен один из этих режимов, например,
последовательные порты и алфавитно-цифровые терминалы чаще используются в
монопольном режиме, а диски – в режиме совместного доступа. Операционная
система должна предоставлять эти устройства в обоих режимах, осуществляя
отслеживание процедур захвата и освобождения монопольно используемых
устройств, а в случае совместного использования оптимизируя последовательность
операций ввода-вывода для различных процессов в целях повышения общей производительности,
если это возможно
Поддержка
широкого спектра драйверов и простота включения нового драйвера в систему
Достоинством подсистемы ввода-вывода любой универсальной ОС является наличие
разнообразного набора драйверов для наиболее популярных периферийных устройств.
Прекрасно спланированная и реализованная операционная система может потерпеть
неудачу на рынке только из-за того, что в ее состав не включен достаточный
набор драйверов и администраторы и пользователи вынуждены искать нужный им
драйвер для имеющегося у них внешнего устройства у производителей оборудования
или, что еще хуже, заниматься его разработкой. Именно в такой ситуации
оказались пользователи первых версий OS/2, и, возможно, это обстоятельство
послужило в свое время не последней причиной сдачи позиций этой неплохой
операционной системы, богатой на драйверы ОС Windows 3.х.
Чтобы операционная система не испытывала недостатка в
драйверах, необходимо наличие четкого, удобного и открытогоинтерфейса между
драйверами и другими компонентами ОС. Такой интерфейс нужен для того, чтобы
драйверы писали не только непосредственные разработчики данной операционной
системы, но и большая армия программистов по всему миру, в первую очередь – тех
предприятий, которые выпускают внешние устройства для компьютеров. Открытость
интерфейса драйверов, т. е. доступность его описания для независимых разработчиков
программного обеспечения (а возможно, также и разработка его на основе
согласительных процедур между ведущими коллективами разработчиков), является
необходимым условием успешного развития операционной системы.
Драйвер взаимодействует, с одной стороны, с модулями ядра ОС (модулями
подсистемы ввода-вывода, модулями системных вызовов, модулями подсистем
управления процессами и памятью и т. д.), а с другой стороны – с контроллерами
внешних устройств. Поэтому существуют два типа интерфейсов: интерфейс
“драйвер-ядро” (Driver Kernel Interface, DKI) и интерфейс “драйвер-устройство”
(Driver Device Interface, DDI). Интерфейс “драйвер-ядро” должен быть стандартизован
в любом случае, а интерфейс “драйвер-устройство” имеет смысл стандартизировать
тогда, когда подсистема ввода-вывода не разрешает драйверу непосредственно
взаимодействовать с аппаратурой контроллера, а выполняет эти операции
самостоятельно. Экранирование драйвера от аппаратуры является весьма полезной
функцией, так как драйвер в этом случае становится независимым от аппаратной
платформы. Подсистема ввода-вывода может поддерживать несколько различных
типов интерфейсов DKI/DDI, предоставляя специфический интерфейс для устройств
определенного класса. Так, в ОС Windows NT для драйверов сетевых адаптеров
существует интерфейс стандарта NDIS (Network Driver Interface Specification), в
то время как драйверы сетевых транспортных протоколов взаимодействуют с
верхними слоями сетевого программного обеспечения по интерфейсу TDI (Transport
Driver Interface).
Для поддержки процесса разработки драйверов операционной системы обычно
выпускается так называемый пакет DDK (Driver Development Kit), представляющий
собой набор соответствующих инструментальных средств – библиотек, компиляторов
и отладчиков.
Динамическая загрузка и выгрузка драйверов
Кроме проблемы разработки новых драйверов, существует также проблема
включения драйвера в состав модулей работающей ОС, т. е. динамической загрузки-выгрузки
драйвера. Так как набор потенциально поддерживаемых данной ОС периферийных
устройств всегда существенно шире набора устройств, которыми ОС должна
управлять при установке на конкретной машине, то ценным свойством ОС является
возможность динамически загружать в оперативную память требуемый драйвер (без
останова ОС) и выгружать его после того, как потребность в поддержке
устройства миновала, что может существенно сэкономить системную область памяти.
Альтернативой динамической загрузке драйверов при изменении текущей
конфигурации внешних устройств компьютера является повторная компиляция кода
ядра с требуемым набором драйверов, что создает между всеми компонентами ядра
статические связи вместо динамических. Например, таким образом решалась данная
проблема в ранних версиях операционной системы UNIX. При статических связях
между ядром и драйверами структура ОС упрощается, но этот подход требует
наличия исходных кодов модулей операционной системы, доступность которых скорее
является исключением (для некоммерческих версий UNIX), а не правилом. Кроме
того, в этом варианте работающую предыдущую версию операционной системы
необходимо остановить и заменить новой, а перерывы в работе ОС в некоторых
применениях могут и не допускаться.
Поддержка
нескольких файловых систем
Диски представляют особый род периферийных устройств,
так как именно на них хранится большая часть как пользовательских, так и
системных данных. Данные на дисках организуются в файловые системы, и свойства
файловой системы во многом определяют свойства самой ОС – ее
отказоустойчивость, быстродействие, максимальный объем хранимых данных.
Популярность файловой системы часто приводит к ее миграции из “родной” ОС в
другие операционные системы – например, файловая система FAT появилась
первоначально в MS-DOS, но затем была реализована в OS/2, семействе MS Windows
и многих реализациях UNIX. Ввиду этого поддержка нескольких популярных файловых
систем для подсистемы ввода-вывода также важна, как и поддержка широкого
спектра периферийных устройств. Важно также, чтобы архитектура подсистемы
ввода-вывода позволяла достаточно просто включать в ее состав новые типы
файловых систем, безнеобходимости переписывания кода. Обычно в операционной
системе имеется специальный слой программного обеспечения, отвечающий за
решение данной задачи, например слой VFS (Virtual File System) в версиях UNIX
на основе кода System V Release 4.
Поддержка синхронных и асинхронных операций ввода-вывода
Операция ввода-вывода
может выполняться по отношению к программному модулю, запросившему операцию, в
синхронном или асинхронном режимах. Синхронный режим означает, что программный
модуль приостанавливает свою работу до тех пор, пока операция ввода-вывода не
будет завершена, а при асинхронном режиме программный модуль продолжает
выполняться в мультипрограммном режиме одновременно с операцией ввода-вывода.
Отличие же заключается в том, что операция ввода-вывода может быть
инициирована не только пользовательским процессом – в этом случае операция
выполняется в рамках системного вызова, но и кодом ядра, например кодом
подсистемы виртуальной памяти для считывания отсутствующей в памяти страницы.
Подсистема
ввода-вывода должна предоставлять своим клиентам (пользовательским процессам и
кодам ядра) возможность выполнять как синхронные, так и асинхронные операции
ввода-вывода, в зависимости от потребностей вызывающей стороны. Системные
вызовы ввода-вывода чаще оформляются как синхронные процедуры в связи с тем,
что такие операции длятся долго и пользовательскому процессу или потоку все
равно придется ждать получения результатов операции для того, чтобы продолжить
свою работу. Внутренние же вызовы операций ввода-вывода из модулей ядра обычно
выполняются в виде асинхронных процедур, так как кодам ядра нужна свобода в
выборе дальнейшего поведения после запроса операции ввода-вывода. Использование
асинхронных процедур приводит к более гибким решениям, так как на основе
асинхронного вызова всегда можно построить синхронный, создав дополнительную
промежуточную процедуру, блокирующую выполнение вызвавшей процедуры до момента
завершения ввода-вывода. Иногда и прикладному процессу требуется выполнить
асинхронную операцию ввода-вывода, например при микроядерной архитектуре,
когда часть кода работает в пользовательском режиме как прикладной процесс, но
выполняет функции операционной системы, требующие полной свободы действий и
после вызова операции ввода-вывода.
27-1 Логическая
организация файловой системы
Одной из основных задач операционной системы является предоставление
удобств пользователю при работе с данными, хранящимися на дисках. Для этого ОС
подменяет физическую структуру хранящихся данных некоторой удобной для пользователя
логической моделью. Логическая модель файловой системы материализуется в виде
дерева каталогов, выводимого на экран такими утилитами, как Norton Commander или
Windows Explorer, в символьных составных именах файлов, в командах работы с
файлами. Базовым элементом этой модели является файл, который так же, как и
файловая система в целом, может характеризоваться как логической, так и
физической структурой.
Цели
и задачи файловой системы
Файл – это
именованная область внешней памяти, в которую можно записывать и из которой
можно считывать данные. Файлы хранятся в памяти, не зависящей от энергопитания,
обычно – на магнитных дисках. Исключением является электронный диск, когда в
оперативной памяти создается структура, имитирующая файловую систему.
Основными целями использования файла являются:
Долговременное
и надежное хранение информации. Долговременность достигается за счет
использования запоминающих устройств, не зависящих от питания, а высокая
надежность определяется средствами защиты доступа к файлам и общей организацией
программного кода ОС, при которой сбои аппаратуры чаще всего не разрушают
информацию, хранящуюся в файлах.
Совместное
использование информации. Файлы обеспечивают естественный и легкий способ
разделения информации между приложениями и пользователями за счет наличия
понятного человеку символьного имени и постоянства хранимой информации и
расположения файла. Файл может быть создан одним пользователем, а затем
использоваться совсем другим пользователем, при этом создатель файла или
администратор могут определить права доступа к нему других пользователей. Эти
цели реализуются в ОС файловой системой.
Файловая система (ФС) – это часть операционной системы, включающая:
совокупность
всех файлов на диске;
наборы
структур данных, используемых для управления файлами, такие, например, как
каталоги файлов, дескрипторы файлов, таблицы распределения свободного и
занятого пространства на диске;
комплекс
системных программных средств, реализующих различные операции над файлами,
такие, как создание, уничтожение, чтение, запись, именование и поиск файлов.
Файловая система распределяет дисковую память, поддерживает именование
файлов, отображает имена файлов в соответствующие адреса во внешней памяти,
обеспечивает доступ к данным, поддерживает разделение, защиту и восстановление
файлов.Таким образом, файловая система играет роль промежуточного слоя,
экранирующего все сложности физической организации долговременного хранилища
данных, и создающего для программ более простую логическую модель этого
хранилища.
Задачи, решаемые ФС, зависят от способа организации вычислительного
процесса в целом. Самый простой тип – это ФС в однопользовательских и однопрограммных
ОС, к числу которых относится, например, MS-DOS. Основные функции в такой ФС
нацелены на решение следующих задач:
именование
файлов;
программный
интерфейс для приложений;
отображение
логической модели файловой системы на физическую организацию хранилища данных;
устойчивость
файловой системы к сбоям питания, ошибкам аппаратных и программных средств.
Типы
файлов
Файловые системы поддерживают несколько функционально различных типов
файлов, в число которых, как правило, входят обычные файлы, файлы-каталоги,
специальные файлы, именованные конвейеры, отображаемые в память файлы и другие.
Обычные файлы,
или просто файлы, содержат информацию произвольного характера, которую
заносит в них пользователь или которая образуется в результате работы системных
и пользовательских программ. Большинство современных операционных систем
(например, UNIX, Windows, OS/2) никак не ограничивает и не контролирует
содержимое и структуру обычного файла. Содержание обычного файла определяется
приложением, которое с ним работает. Например, текстовый редактор создает
текстовые файлы, состоящие из строк символов, представленных в каком-либо
коде. Каталоги – это особый тип файлов, которые содержат системную
справочную информацию о наборе файлов, сгруппированных пользователями по
какому-либо неформальному признаку (например, в одну группу объединяются
файлы, содержащие документы одного договора, или файлы, составляющие один
программный пакет). Каталоги устанавливают соответствие между именами файлов
и их характеристиками, используемыми файловой системой для управления файлами Специальные
файлы – это фиктивные файлы, ассоциированные с устройствами ввода-вывода,
которые используются для унификации механизма доступа к файлам и внешним
устройствам. Специальные файлы позволяют пользователю выполнять операции
ввода-вывода посредством обычных команд записи в файл или чтения из файла. Эти
команды обрабатываются сначала программами файловой системы, а затем на
некотором этапе выполнения запроса преобразуются операционной системой в
команды управления соответствующим устройством.
Иерархическая структура файловой системы
 Пользователи обращаются к файлам по символьным именам.
Однако способности человеческой памяти ограничивают количество имен объектов,
к которым пользователь может обращаться по имени. Иерархическая организация
пространства имен позволяет значительно расширить эти границы. Именно поэтому
большинство файловых систем имеет иерархическую структуру, в которой уровни
создаются за счет того, что каталог более низкого уровня может входить в каталог
более высокого уровня .
Пользователи обращаются к файлам по символьным именам.
Однако способности человеческой памяти ограничивают количество имен объектов,
к которым пользователь может обращаться по имени. Иерархическая организация
пространства имен позволяет значительно расширить эти границы. Именно поэтому
большинство файловых систем имеет иерархическую структуру, в которой уровни
создаются за счет того, что каталог более низкого уровня может входить в каталог
более высокого уровня .
Граф, описывающий иерархию каталогов, может быть деревом или сетью.
Каталоги образуют дерево, если файлу разрешено входить только в один каталог
(рис. 19, б), и сеть – если файл может входить сразу в несколько каталогов
Имена файлов
Все типы файлов имеют символьные имена. В иерархически организованных
файловых системах обычно используются три типа имен файлов: простые, составные
и относительные. в файловых системах NTFS и FAT32, входящих в состав
операционной системы Windows NT, имя файла может содержать до 255 символов.
Монтирование
В общем случае вычислительная система может иметь несколько дисковых
устройств. Даже типичный персональный компьютер обычно имеет один накопитель
на жестком диске, один накопитель на гибких дисках и накопитель для
компакт-дисков. Мощные же компьютеры, как правило, оснащены большим количеством
дисковых накопителей, на которые устанавливаются пакеты дисков. Более того,
даже одно физическое устройство с помощью средств операционной системы может
быть представлено в виде нескольких логических устройств, в частности путем
разбиения дискового пространства на разделы. Возникает вопрос, каким образом
организовать хранение файлов в системе, имеющей несколько устройств внешней
памяти?
Первое решение состоит в том, что на каждом из устройств размещается
автономная файловая система, т. е. файлы, находящиеся на этом устройстве,
описываются деревом каталогов, никак не связанным с деревьями каталогов на
других устройствах. В таком случае для однозначной идентификации файла пользователь
наряду с составным символьным именем файла должен указывать идентификатор
логического устройства. Примером такого автономного существования файловых
систем является операционная система MS-DOS, в которой полное имя файла
включает буквенный идентификатор логического диска. Так, при обращении к
файлу, расположенному на диске А, пользователь должен указать имя этого диска:
A:\privat\letter\uni\let1.doc.
Другим вариантом является такая организация хранения файлов, при
которой пользователю предоставляется возможность объединять файловые системы,
находящиеся на разных устройствах, в единую файловую систему, описываемую
единым деревом каталогов. Такая операция называется монтированием.
Рассмотрим, как осуществляется эта операция на примере ОС UNIX.
После монтирования общей файловой системы для пользователя нет
логической разницы между корневой и смонтированной файловыми системами, в
частности, именование файлов производится так же, как если бы она с самого
начала была единой.
Атрибуты
файлов
Понятие “файл” включает не только хранимые им данные и имя, но и атрибуты.
Атрибуты файла – это информация, описывающая свойства файла. Примеры возможных
атрибутов файла:
тип
файла (обычный файл, каталог, специальный файл и т. п.);
владелец
файла;
создатель
файла;
пароль
для доступа к файлу;
информация
о разрешенных операциях доступа к файлу;
времена
создания, последнего доступа и последнего изменения;
текущий
размер файла;
максимальный
размер файла;
признак
“только для чтения”;
признак
“скрытый файл”;
признак
“системный файл”;
признак
“архивный файл”;
признак
“двоичный/символьный”;
признак
“временный” (удалить после завершения процесса);
признак
блокировки;
длина
записи в файле;
указатель
на ключевое поле в записи;
длина
ключа.
Набор атрибутов файла определяется спецификой файловой системы: в файловых
системах разного типа для характеристики файлов могут использоваться разные
наборы атрибутов. Например, в файловых системах, поддерживающих
неструктурированные файлы, нет необходимости использовать три последних
атрибута в приведенном списке, связанных со структуризацией файла. В однопользовательской
ОС в наборе атрибутов будут отсутствовать характеристики, имеющие отношение к
пользователям и защите, такие как владелец файла, создатель файла, пароль для
доступа к файлу, информация о разрешенном доступе к файлу.
Логическая
организация файла
В общем случае данные, содержащиеся в файле, имеют
некую логическую структуру. Эта структура является базой при
разработкепрограммы, предназначенной для обработки этих данных. Например,
чтобы текст мог быть правильно выведен на экран, программа должна иметь
возможность выделить отдельные слова, строки, абзацы и т. д. Признаками,
отделяющими один структурный элемент от другого, могут служить определенные
кодовые последовательности или просто известные программе значения смещений
этих структурных элементов относительно начала файла. Поддержание структуры
данных может быть либо целиком возложено на приложение, либо в той или иной
степени эту работу может взять на себя файловая система.
В первом случае, когда все действия, связанные со структуризацией и
интерпретацией содержимого файла, целиком относятся к ведению приложения, файл
представляется ФС неструктурированной последовательностью данных. Приложение
формулирует запросы к файловой системе на ввод-вывод, используя общие для всех
приложений системные средства, например, указывая смещение от начала файла и
количество байт, которые необходимо считать или записать. Поступивший к
приложению поток байт интерпретируется в соответствии с заложенной в программе
логикой. Например, компилятор генерирует, а редактор связей воспринимает вполне
определенный формат объектного модуля программы. При этом формат файла, в котором
хранится объектный модуль, известен только этим программам.
Модель файла, в соответствии с которой содержимое файла представляется
неструктурированной последовательностью (потоком) байт, стала популярной вместе
с ОС UNIX, а теперь она широко используется в большинстве современных ОС, в том
числе в Windows NT/2000. Неструктурированная модель файла позволяет легко
организовать разделение файла между несколькими приложениями: разные приложения
могут по-своему структурировать и интерпретировать данные, содержащиеся в
файле.
27-2 Физическая
организация файловой системы
Представление пользователя о файловой системе как об иерархически
организованном множестве информационных объектов имеет мало общего с порядком
хранения файлов на диске. Файл, имеющий образ цельного, непрерывающегося набора
байт, на самом деле очень часто разбросан “кусочками” по всему диску, причем
это разбиение никак не связано с логической структурой файла, например, его
отдельная логическая запись может быть расположена в несмежных секторах диска.
Логически объединенные файлы из одного каталога совсем не обязаны соседствовать
на диске.
Диски, разделы, секторы, кластеры
Основным типом устройства, которое используется в современных
вычислительных системах для хранения файлов, являются дисковые накопители. Эти
устройства предназначены для считывания и записи данных на жесткие и гибкие
магнитные диски. Жесткий диск состоит из одной или нескольких стеклянных или
металлических пластин, каждая из которых покрыта с одной или двух сторон
магнитным материалом. Таким образом, диск в общем случае состоит из пакета
пластин
На каждой стороне каждой пластины размечены тонкие концентрические кольца
– дорожки (traks), на которых хранятся данные. Количество дорожек
зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к
центру диска. Головка может позиционироваться над заданной дорожкой. Головки
перемещаются над поверхностью диска дискретными шагами, каждый шаг
соответствует сдвигу на одну дорожку. Запись на диск осуществляется благодаря
способности головки изменять магнитные свойства дорожки. Совокупность дорожек
одного радиуса на всех поверхностях всех пластин пакета называется цилиндром
(cylinder). Каждая дорожка разбивается на фрагменты, называемые секторами
(sectors), или блоками (blocks), так что все дорожки имеют равное число
секторов, в которые можно максимально записать одно и то же число байт. Сектор
имеет фиксированный для конкретной системы размер, выражающийся степенью
двойки. Чаще всего размер сектора составляет 512 байт. Учитывая, что дорожки
разного радиуса имеют одинаковое число секторов, плотность записи становится
тем выше, чем ближе дорожка к центру.Сектор – наименьшая адресуемая единица
обмена данными дискового устройства с оперативной памятью. Для того чтобы
контроллер мог найти на диске нужный сектор, необходимо задать ему все
составляющие адреса сектора: номер цилиндра, номер поверхности и номер сектора.
Операционная система при работе с диском использует, как правило, собственную
единицу дискового пространства, называемую кластером (cluster). При создании
файла место на диске ему выделяется кластерами. Например, если файл имеет
размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта,
то файлу будет выделено на диске 3 кластера.
Считывание избыточных данных при обмене с
диском
Дорожки и секторы создаются в результате выполнения процедуры физического,
или низкоуровневого, форматирования диска, предшествующей
использованию диска. Для определения границ блоков на диск записывается
идентификационная информация. Низкоуровневый формат диска не зависит от типа
операционной системы, которая этот диск будет использовать.
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого,
или логического, форматирования. При высокоуровневом
форматировании определяется размер кластера и на диск записывается информация,
необходимая для работы файловой системы, в том числе информация о доступном и
неиспользуемом пространстве, о границах областей, отведенных под файлы и
каталоги, информация о поврежденных областях. Кроме того, на диск записывается
загрузчик операционной системы – небольшая программа, которая начинает процесс
инициализации операционной системы после включения питания или рестарта
компьютера.
Раздел – это
непрерывная часть физического диска, которую операционная система представляет
пользователю как логическое устройство (используются также названия логический
диск и логический раздел). Логическое устройство функционирует так, как если бы
это был отдельный физический диск. Именно с логическими устройствами работает
пользователь, обращаяськ ним по символьным именам, используя, например,
обозначения А, В, С, SYS и т. п
На разных логических устройствах одного и того же физического диска
могут располагаться файловые системы разного типа. На рис. 25 показан пример
диска, разбитого на три раздела, в которых установлены две файловых системы
NTFS (разделы С и Е) и одна файловая система FAT (раздел D).
Физическая
организация FAT
Логический раздел, отформатированный под файловую систему FAT, состоит
из следующих областей (рис. 28):
Загрузочный
сектор содержит программу начальной загрузки операционной системы. Вид
этой программы зависит от типа операционной системы, которая будет загружаться
из этого раздела.
Основная
копия FAT содержит информацию о размещении файлов и каталогов на диске.
Резервная
копия FAT.
Корневой
каталог занимает фиксированную область размером в 32 сектора (16 Кбайт),
что позволяет хранить 512 записей о файлах и каталогах, так как каждая запись
каталога состоит из 32 байт.
Область
данных предназначена для размещения всех файлов и всех каталогов, кроме
корневого каталога.
Физическая структура файловой системы FAT
Файловая система FAT поддерживает всего два типа файлов: обычный файл и
каталог. Файловая система распределяет память только из области данных, причем
использует в качестве минимальной единицы дискового пространства кластер.
Таблица FAT (как основная копия, так и резервная) состоит из массива
индексных указателей, количество которых равно количеству кластеров области
данных. Между кластерами и индексными указателями имеется взаимно однозначное
соответствие – нулевой указатель соответствует нулевому кластеру и т. д.
Индексный указатель может принимать следующие значения, характеризующие
состояние связанного с ним кластера:
кластер
свободен (не используется);
кластер
используется файлом и не является последним кластером файла; в этом случае
индексный указатель содержит номер следующего кластера файла;
последний
кластер файла;
дефектный
кластер;
резервный
кластер.
Таблица FAT является общей для всех файлов раздела. В исходном состоянии
(после форматирования) все кластеры раздела свободны и все индексные указатели
(кроме тех, которые соответствуют резервным и дефектным блокам) принимают
значение “кластер свободен”. При размещении файла ОС просматривает FAT, начиная
с начала, и ищет первый свободный индексный указатель. После его обнаружения в
поле записи каталога “номер первого кластера” фиксируется номер этого
указателя. В кластер с этим номером записываются данные файла, он становится
первым кластером файла. Если файл умещается в одном кластере, то в указатель,
соответствующий данному кластеру, заносится специальное значение “последний
кластер файла”. Если же размер файла больше одного кластера, то ОС продолжает
просмотр FAT и ищет следующий указатель на свободный кластер. После его
обнаружения в предыдущий указатель заносится номер этого кластера, который
теперь становится следующим кластером файла. Процесс повторяется до тех пор,
пока не будут размещены все данные файла. Таким образом создается связный
список всех кластеров файла.
Физическая
организация s5 и ufs
Файловые системы s5 (получившие название от System V, родового имени нескольких
версий ОС UNIX, разработанных в Bell Labs компании AT&T) и ufs (UNIX File
System) используют очень близкую физическую модель. Это не удивительно, так как
система ufs является развитием системы s5. Файловая система ufs расширяет
возможности s5 по поддержке больших дисков и файлов, а также повышает ее
надежность.
Расположение файловой системы s5 на диске иллюстрирует рис. 30. Раздел
диска, где размещается файловая система, делится на четыре области:
загрузочный
блок;
суперблок
(superblock) содержит самую общую информацию о файловой системе: размер
файловой системы, размер области индексных дескрипторов, число индексных
дескрипторов, список свободных блоков и список свободных индексных
дескрипторов, а также другую административную информацию;
область
индексных дескрипторов (mode list), порядок расположения индексных
дескрипторов в которой соответствует их номерам;
область
данных, в которой расположены как обычные файлы, так и файлы-каталоги, в
том числе и корневой каталог; специальные файлы представлены в файловой системе
только записями в соответствующих каталогах и индексными дескрипторами
специального формата, но места в области данных не занимают.
Основной особенностью физической организации файловой системы s5 является
отделение имени файла от его характеристик, хранящихся в отдельной структуре,
называемой индексным дескриптором (inode). Индексный дескриптор в
s5 имеет размер 64 байта и содержит данные о типе файла, адресную информацию,
привилегии доступа к файлу и некоторую другую информацию, а именно:
идентификатор
владельца файла;
тип
файла; файл может быть файлом обычного типа, каталогом, специальным файлом, а
также конвейером или символьной связью;
права
доступа к файлу;
временные
характеристики: время последней модификации файла, время последнего обращения
к файлу, время последней модификации индексного дескриптора;
число
ссылок на данный индексный дескриптор, равный количеству псевдонимов файла;
адресная
информация;
размер
файла в байтах.
Запись о файле в каталоге состоит всего из двух полей: символьного
имени файла и номера индексного дескриптора. Например, на рис. 31 показана
информация, содержащаяся в каталоге /user.
NTFS
Файловая система NTFS была разработана в качестве основной файловой
системы для ОС Windows NT в начале 90-х годов с учетом опыта разработки
файловых систем FAT и HPFS (основная файловая система для OS/2), а также других
существовавших в то время файловых систем. Основными отличительными свойствами
NTFS являются:
поддержка
больших файлов и больших дисков объемом до 264 байт;
восстанавливаемость
после сбоев и отказов программ и аппаратуры управления дисками;
высокая
скорость операций, в том числе и для больших дисков;
низкий
уровень фрагментации, в том числе и для больших дисков;
гибкая
структура, допускающая развитие за счет добавления новых типов записей и
атрибутов файлов с сохранением совместимости с предыдущими версиями ФС;
устойчивость
к отказам дисковых накопителей;
поддержка
длинных символьных имен;
контроль
доступа к каталогам и отдельным файлам.
Структура тома NTFS. В отличие
от разделов FAT и s5/ufs все пространство тома NTFS представляет собой либо
файл, либо часть файла. Основой структуры тома NTFS является главная таблица
файлов (Master File Table, MFT), которая содержит по крайней мере одну
запись для каждого файла тома, включая одну запись для самой себя. Каждая
запись MFT имеет фиксированную длину, зависящую от объема диска, – 1, 2 или 4
Кбайт.
Все файлы на томе NTFS идентифицируются номером файла, который
определяется позицией файла в MFT. Этот способ идентификации файла близок к
способу, используемому в файловых системах s5 и ufs, где файл однозначно
идентифицируется номером его записи в области индексных дескрипторов.
Весь том NTFS состоит из последовательности кластеров, что отличает эту
файловую систему от рассмотренных ранее, где на кластеры делилась только
область данных. Порядковый номер кластера в томе NTFS называется логическим
номером кластера (Logical Cluster Number, LCN). Файл NTFS также
состоит из последовательности кластеров, при этом порядковый номер кластера
внутри файла называется виртуальным номером кластера
(Virtual Cluster Number, VCN).
Базовая единица распределения дискового пространства для файловой
системы NTFS – непрерывная область кластеров, называемая отрезком. В
качестве адреса отрезка NTFS использует логический номер его первого кластера,
а также количество кластеров в отрезке k, т. е. пара (LCN, k). Таким образом,
часть файла, помещенная в отрезок и начинающаяся с виртуального кластера VCN,
характеризуется адресом, состоящим из трех чисел (VCN, LCN, k).
Для хранения
номера кластера в NTFS используются 64-разрядные указатели, что дает
возможность поддерживать тома и файлы размером до 264 кластеров. При
размере кластера в 4 Кбайт это позволяет использовать тома и файлы, состоящие
из 64 миллиардов килобайт. Защита от сбоев и несанкционированного доступа
28
Основные понятия безопасности
Безопасная информационная система – это система, которая, во-первых,
защищает данные от несанкционированного доступа, во-вторых, всегда готова
предоставить их своим пользователям, а в-третьих, надежно хранит информацию и
гарантирует неизменность данных. Таким образом, безопасная система по определению
обладает свойствами конфиденциальности, доступности и целостности.
Конфиденциальность – гарантия того, что секретные данные будут доступны только тем
пользователям, которым этот доступ разрешен (такие пользователи называются
авторизованными).
Доступность –
гарантия того, что авторизованные пользователи всегда получат доступ к данным.
Целостность –
гарантия сохранности данными правильных значений, которая обеспечивается
запретом для неавторизованных пользователей каким-либо образом изменять,
модифицировать, разрушать или создавать данные.
Понятия конфиденциальности, доступности и целостности могут быть
определены не только по отношению к информации, но и к другим ресурсам
вычислительной сети, например, внешним устройствам или приложениям. Существует
множество системных ресурсов, возможность “незаконного” использования которых
может привести к нарушению безопасности системы. Например, неограниченный
доступ к устройству печати позволяет злоумышленнику получать копии
распечатываемых документов, изменять параметры настройки, что может привести к
изменению очередности работ и даже к выводу устройства из строя. Свойство
конфиденциальности, примененное к устройству печати, можно интерпретировать
так, что доступ к устройству имеют те и только те пользователи, которым этот
доступ разрешен, причем они могут выполнять только те операции с устройством,
которые для них определены. Свойство доступности устройства означает его
готовность к использованию всякий раз, когда в этом возникает необходимость. А
свойство целостности может быть определено как свойство неизменности
параметров настройки данного устройства.
Любое действие, которое направлено на нарушение конфиденциальности,
целостности и/или доступности информации, а также на нелегальное использование
других ресурсов сети, называется угрозой. Реализованная угроза
называется атакой. Риск – это вероятностная оценка величины
возможного ущерба, который может понести владелец информационного ресурса в
результате успешно проведенной атаки. Значение риска тем выше, чем более уязвимой
является существующая система безопасности и чем выше вероятность реализации
атаки.
Угрозы могут быть разделены на умышленные и неумышленные.
Неумышленные
угрозы вызываются ошибочными действиями лояльных сотрудников,
становятся следствием их низкой квалификации или безответственности. Кроме
того, к такому роду угроз относятся последствия ненадежной работы программных
и аппаратных средств системы. Так, например, из-за отказа диска, контроллера
диска или всего файлового сервера могут оказаться недоступными данные,
критически важные для работы предприятия. Поэтому вопросы безопасности так
тесно переплетаются с вопросами надежности, отказоустойчивости технических
средств. Угрозы безопасности, которые вытекают из ненадежности работы
программно-аппаратных средств, предотвращаются путем их совершенствования,
использования резервирования на уровне аппаратуры (RAID-массивы,
многопроцессорные компьютеры, источники бесперебойного питания, кластерные
архитектуры) или на уровне массивов данных (тиражирование файлов, резервное
копирование).
Умышленные угрозы
могут ограничиваться либо пассивным чтением данных или мониторингом системы,
либо включать в себя активные действия, например, нарушение целостности и
доступности информации, приведение в нерабочее состояние приложений и
устройств. Так, умышленные угрозы возникают в результате деятельности хакеров
и явно направлены на нанесение ущерба.
В вычислительных сетях можно выделить следующие типы умышленных угроз:
незаконное
проникновение в один из компьютеров сети под видом легального пользователя;
разрушение
системы с помощью программ-вирусов;
нелегальные
действия легального пользователя;
“подслушивание”
внутрисетевого трафика.
Незаконное проникновение
может быть реализовано через уязвимые места в системе безопасности с
использованием недокументированных возможностей операционной системы. Эти
возможности могут позволить злоумышленнику “обойти” стандартную процедуру,
контролирующую вход в сеть.
Другим способом незаконного проникновения в сеть является использование
“чужих” паролей, полученных путем подглядывания, расшифровки файла паролей,
подбора паролей или получения пароля путем анализа сетевого трафика. Особенно
опасно проникновение злоумышленника под именем пользователя, наделенного
большими полномочиями, например администратора сети. Для того чтобы завладеть
паролем администратора, злоумышленник может попытаться войти в сеть под именем
простого пользователя. Поэтому очень важно, чтобы все пользователи сети
сохраняли свои пароли в тайне, а также выбирали их так, чтобы максимально
затруднить угадывание.
Еще один способ получения пароля – это внедрение в чужой компьютер
“троянского коня”. Так называют резидентную программу, работающую без ведома
хозяина данного компьютера и выполняющую действия, заданные злоумышленником. В
частности, такого рода программа может считывать коды пароля, вводимого
пользователем во время логического входа в систему.
Программа “троянский конь” всегда маскируется под какую-нибудь полезную
утилиту или игру, а производит действия, разрушающие систему. По такому принципу
действуют и программы-вирусы, отличительной особенностью которых
является способность “заражать” другие файлы, внедряя в них свои собственные
копии. Чаще всего вирусы поражают исполняемые файлы. Когда такой исполняемый
код загружается в оперативную память для выполнения, вместе с ним получает
возможность исполнить свои вредительские действия вирус. Вирусы могут привести
к повреждению или даже полной утрате информации.
Нелегальные действия легального пользователя – этот тип угроз исходит от легальных пользователей
сети, которые, используя свои полномочия, пытаются выполнять действия,
выходящие за рамки их должностных обязанностей. Например, администратор сети
имеет практически неограниченные права на доступ ко всем сетевым ресурсам.
Однако на предприятии может быть информация, доступ к которой администратору
сети запрещен. Для реализации этих ограничений могут быть предприняты
специальные меры, такие, например, как шифрование данных, но и в этом случае
администратор может попытаться получить доступ к ключу. Нелегальные действия
может попытаться предпринять и обычный пользователь сети. Существующая
статистика говорит о том, что едва ли не половина всех попыток нарушения
безопасности системы исходит от сотрудников предприятия, которые как раз и
являются легальными пользователями сети.
«Подслушивание» внутрисетевого трафика – это незаконный мониторинг сети, захват и анализ
сетевых сообщений. Существует много доступных программных и аппаратных
анализаторов трафика, которые делают эту задачу достаточно тривиальной.
Для обеспечения безопасности информации в компьютерах, особенно в
офисных системах и компьютерных сетях, проводятся различные мероприятия,
объединяемые понятием “система защиты информации”.
Система защиты информации – это
совокупность организационных (административных) и технологических мер, программно-технических
средств, правовых и морально-этических норм, направленных на противодействие
угрозам нарушителей с целью сведения до минимума возможного ущерба
пользователям и владельцам системы.
На практике при построении системы защиты информации сложились два
подхода: фрагментарный и комплексный. В первом случае мероприятия по защите
направляются на противодействие вполне определенным угрозам при строго определенных
условиях, например обязательная проверка носителей антивирусными программами,
применение криптографических систем шифрования и т.д. При комплексном подходе
различные меры противодействия угрозам объединяются, формируя так называемую
архитектуру безопасности систем.
Архитектура безопасности – комплексное решение вопросов безопасности
вычислительной системы, где выделяются угрозы безопасности, службы безопасности
и механизмы обеспечения безопасности.
Учитывая важность, масштабность и сложность решения проблемы
сохранности и безопасности информации, рекомендуется разрабатывать архитектуру
безопасности в несколько этапов:
анализ
возможных угроз;
разработка
системы защиты;
реализация
системы защиты;
сопровождение
системы защиты.
Этап разработки системы защиты информации предусматривает
использование комплексов мер и мероприятий
организационно-административного, организационно-технического,
программно-аппаратного, технологического, правового, морально-этического
характера и др.
Организационно-административные средства защиты сводятся к регламентации доступа к информационным и
вычислительным ресурсам, функциональным процессам систем обработки данных, к
регламентации деятельности персонала и др. Их цель – в наибольшей степени затруднить
или исключить возможность реализации угроз безопасности. Наиболее типичные
организационно-административные меры – это:
создание
контрольно-пропускного режима на территории, где располагаются ЭВМ и другие
средства обработки информации;
допуск
к обработке и передаче конфиденциальной информации только проверенных
должностных лиц; хранение магнитных и иных носителей информации, представляющих
определенную тайну, а также регистрационных журналов в сейфах, недоступных для
посторонних лиц;
организация
зашиты от установки прослушивающей аппаратуры в помещениях, связанных с
обработкой информации и т.д.
Технические средства защиты – системы охраны территорий и помещений с помощью
экранирования машинных залов и организации контрольно-пропускных систем.
Технические средства призваны создать некоторую физически замкнутую
среду вокруг объекта и элементов защиты. В этом случае используются такие
мероприятия, как:
установка
средств физической преграды защитного контура помещений, где ведется обработка
информации (кодовые замки; охранная сигнализация – звуковая, световая,
визуальная без записи и с записью на видеопленку);
ограничение
электромагнитного излучения путем экранирования помещений, где происходит
обработка информации, листами из металла или специальной пластмассы и т.д.
Программные средства и методы защиты активнее и шире других применяются для защиты
информации в персональных компьютерах и компьютерных сетях, реализуя такие
функции защиты, как разграничение и контроль доступа к ресурсам; регистрация и
анализ протекающих процессов, событий, пользователей; предотвращение возможных
разрушительных воздействий на ресурсы; криптографическая защита информации,
т.е. шифровка данных; идентификация и аутентификация пользователей и процессов
и др.
Для надежной защиты информации и выявления случаев неправомочных
действий проводится регистрация работы системы: создаются специальные дневники
и протоколы, в которых фиксируются все действия, имеющие отношение к защите
информации в системе. Фиксируются время поступления заявки, ее тип, имя
пользователя и терминала, с которого инициализируется заявка.
Используются также специальные программы для тестирования системы
защиты. Периодически или в случайно выбранные моменты времени они проверяют
работоспособность аппаратных и программных средств защиты.
Технологические средства защиты информации – это комплекс мероприятий, органично встраиваемых в
технологические процессы преобразования данных. Среди них:
создание
архивных копий носителей;
ручное
или автоматическое сохранение обрабатываемых файлов во внешней памяти
компьютера;
регистрация
пользователей компьютерных средств в журналах;
автоматическая
регистрация доступа пользователей к тем или иным ресурсам и т.д.
К правовым и морально-этическим мерам и средствам защиты
относятся действующие в стране законы, нормативные акты, регламентирующие
правила обращения с информацией и ответственность за их нарушение; нормы
поведения (сложившиеся в виде устава или неписаные), соблюдение которых способствует
защите информации.
29-1
Базовые технологии безопасности ОС
Основные средства защиты, встроенные в ОС
Средства защиты, встроенные в ОС, занимают особое место в системе
безопасности. Их основной задачей является защита информации, определяющей
конфигурацию системы, и затем – пользовательских данных. Такой подход представляется
естественным, поскольку возможность изменять конфигурацию делает механизмы
защиты бессмысленными.
Проблема защиты информации в компьютерных системах напрямую связана с
решением двух главных вопросов:
обеспечение
сохранности информации,
контроль
доступа к информации (обеспечение конфиденциальности).
Системные средства аутентификации пользователей. Первое,
что должна проверить операционная система в том случае, если она обладает хотя
бы минимальными средствами защиты, – это следует ли ей взаимодействовать с
субъектом, который пытается получить доступ к каким-либо информационным
ресурсам. Для этого существует список именованных пользователей, в соответствии
с которым может быть построена система разграничения доступа.
Под идентификацией понимается определение тождественности
пользователя или пользовательского процесса, необходимое для управления
доступом. После идентификации обычно производится аутентификация. Под аутентификацией
пользователя (субъекта) понимается установление его подлинности. При входе
в систему пользователь должен предъявить идентифицирующую информацию,
определяющую законность входа и права на доступ. Эта информация проверяется,
определяются полномочия пользователя (аутентификация), и пользователю
разрешается доступ к различным объектам системы (авторизация). Под авторизацией
(санкционированием) подразумевается предоставление разрешения доступа к
ресурсу системы.
Разграничение доступа пользователей к ресурсам. Управление
доступом может быть достигнуто при использовании дискреционного или мандатного
управления доступом
Дискреционное управление доступом – наиболее общий тип управления доступом. Основной
принцип этого вида защиты состоит в том, что индивидуальный пользователь или
программа, работающая от имени пользователя, имеет возможность явно определить
типы доступа, которые могут осуществить другие пользователи (или программы,
выполняемые от их имени) к информации, находящейся в ведении данного
пользователя. Дискреционное управление
доступом отличается от мандатной защиты тем, что оно реализует решения по
управлению доступом, принятые пользователем.
Мандатное управление доступом реализуется на основе результатов сравнения уровня
допуска пользователя и степени конфиденциальности информации.
Существуют механизмы управления доступом, поддерживающие степень
детализации управления доступом на уровне следующих категорий:
владелец
информации;
заданная
группа пользователей;
все другие авторизованные пользователи.
Это позволяет владельцу файла (или каталога) иметь права доступа,
отличающиеся от прав всех других пользователей и определять особые права
доступа для указанной группы людей или всех остальных пользователей.
В общем случае существуют следующие права доступа:
доступ
по чтению;
доступ
по записи;
дополнительные
права доступа (только модификацию или только добавление);
доступ
для выполнения всех операций.
Управление доступом пользователя может осуществляться на уровне
каталогов или на уровне файлов. Управление доступом на уровне каталога приводит
к тому, что права доступа для всех файлов в каталоге становятся одинаковыми.
Например, пользователь, имеющий доступ по чтению к каталогу, может читать (и,
возможно, копировать) любой файл в этом каталоге. Права доступа к каталогу
могут также обеспечить явный запрет доступа, который предотвращает любой
доступ пользователя к файлам в каталоге.
Разделяемые
файлы позволяют осуществлять параллельный доступ к файлу нескольких
пользователей одновременно. Блокированный файл будет разрешать доступ к
себе только одному пользователю в данный момент. Если файл доступен только по
чтению, назначение его разделяемым позволяет группе пользователей параллельно
читать его.
Механизмы привилегий
позволяют авторизованным пользователям игнорировать ограничения на доступ или,
другими словами, легально обходить управление доступом, чтобы выполнить
какую-либо функцию, получить доступ к файлу, и т.д. Механизм привилегий должен
включать концепцию минимальных привилегий (принцип, согласно которому каждому
субъекту в системе предоставляется наиболее ограниченное множество привилегий,
необходимых для выполнения задачи).
Принцип минимальных
привилегий должен применяться, например, при выполнении функции резервного
копирования. Пользователь, который авторизован выполнять функцию резервного
копирования, должен иметь доступ по чтению ко всем файлам, чтобы копировать их
на резервные носители информации. Однако пользователю нельзя предоставлять
доступ по чтению ко всем файлам через механизм управления доступом.
Средство проверки корректности конфигурации ОС.
Операционная система имеет большое количество настроек и конфигурационных
файлов, что позволяет адаптировать ОС для нужд конкретных пользователей
информационной системы. Однако это создает опасность появления слабых мест,
поэтому для проверки целостности и корректности текущей конфигурации в ОС
должна быть предусмотрена специальная утилита.
Инструмент системного аудита. Вопросы
информационной безопасности не могут успешно решаться, если нет средств
контроля за происходящими событиями, поскольку только имея хронологическую
запись всех производимых пользователями действий, можно оперативно выявлять
случаи нарушения режима информационной безопасности, определять причины
нарушения, а также находить и устранять потенциально слабые места в системе
безопасности. Кроме того, наличие аудита в системе играет роль сдерживающего
фактора: зная, что действия фиксируются, многие злоумышленники не рискуют
совершать заведомо наказуемых действий.
Сетевые средства защиты. Защита
информации на сетевом уровне имеет определенную специфику. Если на системном
уровне проникнуть в систему можно было лишь в результате раскрытия
пользовательского пароля, то в случае распределенной конфигурации становится
возможен перехват пользовательских имени и пароля техническими средствами.
Например, стандартный сетевой сервис telnet пересылает пользовательское имя и
пароль в открытом виде. Это заставляет вновь рассматривать задачу
аутентификации пользователей, но уже в распределенном случае, включая и
аутентификацию машин-клиентов. Ядро безопасности ОС
Ядро безопасности (ЯБ) ОС – набор программ, управляющих частями системы,
ответственными за безопасность. ЯБ реализует политику обеспечения безопасности
системы. Полномочия ядра ассоциируются с процессами. Они позволяют
процессу выполнить определенные действия, если процесс обладает необходимой
привилегией.
Полномочия подсистем ассоциируются с пользователями. Они позволяют пользователю выполнять
определенное действие посредством команд, отнесенных к подсистеме.
Подсистема –
набор файлов, устройств и команд, служащих определенной цели. Полномочия ядра
заносятся в “множество полномочий”, ассоциированное с каждым процессом.
Полномочия устанавливаются по умолчанию, пользователь может их и переустановить.
Кроме того, ЯБ предоставляет полный “след” действий – журнал учета.
Журнал содержит записи о каждой попытке доступа субъекта к субъекту (успешные
и неудачные), о каждом изменении субъекта, объекта, характеристик системы.
Подсистема учета управляется специальным администратором учета. Администратор
учета управляет собранной информацией, которая помогает администратору
выяснить, что случилось с системой, когда и кто в этом участвовал.
Одна из важных функций ЯБ – локализация потенциальных проблем,
связанных с безопасностью. Ограничительный механизм состоит из:
парольных ограничений;
ограничений на использование терминалов;
входных ограничений.
Администратор опознавания может позволять пользователям самостоятельно
вводить пароли или использовать сгенерированные пароли. Пароль может
подвергаться проверке на очевидность.
Определяются следующие состояния паролей:
пароль корректен;
пароль просрочен (пользователь может войти в
систему и изменить пароль, если у него есть на это полномочие);
пароль закрыт (пользователь заблокирован,
необходима помощь администратора).
Пользователи часто не подчиняются принудительной периодической смене
паролей, восстанавливая предыдущее значение. Чтобы препятствовать этому, кроме
максимального, устанавливается еще и минимальное время действия паролей.
Поддерживается возможность генерировать отчеты о различных аспектах
функционирования системы: пароли, терминалы, входы.
Ни одна ОС не является абсолютно безопасной. Возможны следующие пути
вторжения:
некто может узнать пароль другого
пользователя или получить доступ к терминалу, с которого в систему вошел другой
пользователь;
пользователь
с полномочиями злоупотребляет своими привилегиями;
хорошо
осведомленный пользователь получил неконтролируемый доступ непосредственно к
компьютеру.
Опасно предоставлять оборудование для открытого доступа пользователям.
Любые средства защиты системы будут бесполезны, если оборудование, носители
сохраненных версий и дистрибутивы не защищены.
Подсистема учета ОС регистрирует происходящие в системе события, важные
с точки зрения безопасности, в журнале учета, который впоследствии можно
анализировать. Учет позволяет анализировать собранную информацию, выявляя
способы доступа к объектам и действия конкретных пользователей. Подсистема
учета с большой степенью надежности гарантирует, что попытки обойти механизм
защиты и контроля полномочий будут учтены.
Сетевые серверы – это ворота, через которые внешний мир получает
доступ к информации на компьютере. Поэтому ЯБ должно:
определить,
какую информацию/действие запрашивает клиент;
решить,
имеет ли клиент право на информацию, которую запрашивает сервис;
передать
требуемую информацию/выполнить действие.
Ошибки в сервере и “черные ходы” могут подвергнуть опасности защиту
всего компьютера, открывая систему любому пользователю в сети, осведомленному
об изъяне. Даже относительно безобидная программа может привести к разрушению
всей системы.
29-2
Механизм идентификации и аутентификации в ОС Windows NT
Механизм идентификации и аутентификации пользователя в ОС Windows NT
реализуется специальным процессом Winlogon, который активизируется на начальном
этапе загрузки ОС и остается активным на протяжении всего периода ее
функционирования. Ядро операционной системы регулярно проверяет состояние
данного процесса и в случае его аварийного завершения происходит аварийное
завершение работы всей операционной системы.
При входе в систему пользователь передает в системную функцию LogonUser
свое имя, пароль и имя рабочей станции или домена, в котором данный
пользователь зарегистрирован. Если пользователь успешно идентифицирован,
функция LogonUser возвращает указатель на маркер доступа пользователя, который
в дальнейшем используется при любом его обращении к защищенным объектам
системы.
Когда пользователь еще не вошел в систему, Winlogon находится в
состоянии 1, пользователю предлагается идентифицировать себя и предоставить
подтверждающую информацию (в стандартной конфигурации – пароль). Если
информация, введенная пользователем, дает ему право входа в систему,
активизируется оболочка системы (как правило, Program Manager) и Winlogon
переключается в состояние 2.
Когда пользователь вошел в систему, Winlogon находится в состоянии 2.
В этом состоянии пользователь может прекратить работу, выйдя из системы, или
заблокировать рабочую станцию. В первом случае завершает все процессы,
связанные с завершающимся сеансом, и переключается в состояние 1. Во втором
случае Winlogon выводит на экран сообщение о том, что рабочая станция
заблокирована, и переключается в состояние 3.
В состоянии 3 Winlogon выводит на экран приглашение
пользователю идентифицировать себя и разблокировать рабочую станцию. Это может
сделать либо заблокировавший ее пользователь, либо администратор. В первом
случае система возвращается в то состояние, в котором находилась
непосредственно перед блокировкой, и переключается в состояние 2. Во втором
случае все процессы, связанные с текущим сеансом, завершаются, и Winlogon
переключается в состояние 1.
Когда рабочая станция заблокирована, фоновые процессы, запущенные
пользователем до блокировки, продолжают выполняться.
Механизмы
защиты в ОС UNIX
Идентификация и аутентификация. Рассмотрим
стандартную процедуру идентификации и аутентификации пользователя. Система
ищет имя пользователя в файле /etc/passwd и, если пользователь
идентифицируется (т. е. его имя найдено), аутентификация заключается в сравнении
образа аутентификации от введенного пароля с эталоном. При этом предусмотрены
некоторые правила относительно характеристик пароля и возможности его
изменения. Но, как показала практика, этих правил недостаточно для реализации
надежной защиты.
В надежной системе стандартная процедура идентификации и аутентификации
расширена. В ней предусмотрено больше правил, касающихся типов используемых
паролей. Введены процедуры генерации и изменения паролей. Изменены
местоположение и механизм защиты некоторых частей базы данных паролей.
Администратору аутентификации предоставлены дополнительные возможности для
контроля за действиями пользователей.
Для усиления качественных и количественных характеристик процедур
идентификации и аутентификации в UNIX существуют следующие средства.
Задание
администратором учета пользователей и терминалов определенных требований на
пароли:
1) ограничение минимальной длины вводимого пользователем пароля;
2) требование наличия в пароле обязательного минимального количества букв
нижнего регистра, букв верхнего регистра, цифр и специальных символов;
3) запрещение пользователю введения собственных паролей; разрешение
вводить только пароли, созданные системой.
Задание
администратором временных ограничений по частоте сменяемости и времени жизни
паролей. При этом для удобства пользователя возможно задание интервала между
началом требования смены пароля и окончанием срока его действия.
Автоматическое
блокирование пользователя на входе в систему по старости пароля, по числу неуспешных
попыток входа.
Задание
количества и номеров терминалов для входа в систему для каждого пользователя.
Проверка
системой паролей пользователей при вводе на их семантические и контекстуальные
особенности (вхождение идентификатора, имени пользователя, повторяемость
символов и т. д.).
Хранение
зашифрованных паролей не в /etc/passwd, как в старых версиях, поскольку этот
файл открыт для чтения всем пользователям, а в закрытом от доступа отдельном
файле.
Получение
статистической информации по времени работы пользователя в системе, его
блокировке, номеру терминала и т. д.
Помимо этого существует возможность блокирования по числу неуспешных
попыток входа не только пользователя, но и терминала. При этом можно задать
интервал времени, который должен пройти между попытками регистрации. Также
предусмотрено ведение записей об успешных и неуспешных попытках входа в
систему.
Хорошо себя зарекомендовало использование командного интерпретатора
rsh. Пользователь, во-первых, не может перейти никуда из своего домашнего
справочника. Во-вторых, он может использовать только команды из тех
справочников, которые определены в переменной окружения PATH. При этом изменить
значение переменной окружения PATH пользователь не может. В-третьих, пользователь
не может задавать полные имена программных файлов и перенаправлять потоки
ввода-вывода.
Защита файловой системы. Очевидно,
что наибольшее внимание в вопросах защиты операционной системы должно быть
уделено защите файловой системы.
Каждый файл в системе имеет уникальный индекс. Индекс – это управляющий
блок. В литературе он также называется индексным дескриптором, i-node, или
i-узлом. Индекс содержит информацию, необходимую любому процессу для того,
чтобы обратиться к файлу, например, права собственности на файл, права доступа
к файлу, размер файла и расположение данных файла в файловой системе. Процессы
обращаются к файлам, используя четко определенный набор системных вызовов и
идентифицируя файл строкой символов, выступающих в качестве составного имени
файла. Каждое составное имя однозначно определяет файл, благодаря чему ядро
системы преобразует это имя в индекс файла. Индексы существуют на диске в
статической форме, и ядро считывает их в память прежде, чем начать с ними
работать.
Традиционно в файловых системах ОС UNIX за доступ ко всем типам файлов
(файлы, каталоги и специальные файлы) отвечают 9 бит, которые хранятся в
i-узле.
Первая группа из 3 бит определяет права доступа к файлу для его
владельца, вторая – для членов группы владельца, третья – для всех остальных
пользователей.
Например, права доступа “rwxr-xr—” к файлу означают, что владелец
файла имеет полный доступ, члены группы имеют возможность чтения и выполнения,
все остальные имеют возможность только читать данный файл. Для каталога
установка бита выполнения “х” означает возможность поиска (извлечения) файлов
из этого каталога.
Такая система защиты файлов существует достаточно
давно и невызывает существенных нареканий. Действительно, для того чтобы
вручную, т. е. не используя системные вызовы и команды, изменить права доступа
к файлу, необходимо иметь доступ к области i-узлов. Для того чтобы иметь доступ
к области i-узлов, необходимо изменить права доступа специального файла
(например, /dev/root), биты доступа которого также хранятся в области i-узлов.
Иными словами, если случайно или умышленно не испортить права доступа
ко всем файлам системы, установленные по умолчанию (обычно правильно) при
инсталляции, то можно с большой степенью вероятности гарантировать безопасность
работы системы.
Некоторые UNIX-системы (например, Solaris) предоставляют дополнительные
возможности по управлению правами доступа к файлам путем использования списков
управления доступом (Access Control List). Данный механизм позволяет для
каждого пользователя или для отдельной группы установить индивидуальные права
доступа к заданному файлу. При этом списки доступа сохраняются всеми системными
средствами копирования и архивирования. Нельзя сказать, что введение этого механизма
принципиально улучшает защиту файлов, но он вносит некоторую гибкость в
процедуру формирования прав доступа к файлам.
Контроль целостности системы. Целостность
системы должна контролироваться ОС. В ОС UNIX контроль целостности системы
производится рядом специальных команд.
Стандартная последовательность действий после возникновения сбоя в
системе или каких-либо других отклонений следующая:
1) выполнение проверки файловой системы;
2) составление контрольного отчета;
3) проверка базы данных аутентификации;
4) проверка разрешений для системных файлов.
Средства аудита. Будем
считать, что действие контролируется, если можно вычислить реального
пользователя, который его осуществил. Система контроля UNIX регистрирует
события в системе, связанные с защитой информации, записывая их в контрольный
журнал. В контрольных журналах возможна фиксация проникновения в систему и
неправильного использования ресурсов. Контроль позволяет просматривать
собранные данные для изучения видов доступа к объектам и наблюдения за
действиями отдельных пользователей и их процессов. Попытки нарушения защиты и
механизмов авторизации контролируются. Использование системы контроля дает
высокую степень гарантии обнаружения попыток обойти механизмы обеспечения
безопасности. Поскольку события, связанные с защитой информации, контролируются
и учитываются вплоть до выявления конкретного пользователя, система контроля
служит сдерживающим средством для пользователей, пытающихся некорректно
использовать систему.
В соответствии с требованиями к надежным системам ОС должна создавать,
поддерживать и защищать журнал регистрационной информации, относящейся к
доступу к объектам, контролируемым ОС. При этом должна быть возможность
регистрации следующих событий:
1) использование механизма идентификации и аутентификации;
2) внесение объектов в адресное пространство пользователя (например,
открытие файла);
3) удаление объектов;
4) действия администраторов;
5) другие события, затрагивающие информационную безопасность.
Каждая регистрационная запись должна включать следующие поля:
1) дата и время события;
2) идентификатор пользователя;
3) тип события;
4) результат действия.
Система контроля UNIX использует системные вызовы и утилиты для
классификации действий пользователей, подразделяя их на события различного
типа. Например, при возникновении события типа “DAC Denials” (отказ доступа при
реализации механизма избирательного разграничения доступа) регистрируются
попытки такого использования объекта, которые не допускаются разрешениями для
этого объекта. Иными словами, если пользовательский процесс пытается писать в файл
с доступом “только для чтения”, то возникает событие типа “DAC Denials”. Если
просмотреть контрольный журнал, то легко можно увидеть повторяющиеся попытки
доступа к файлам, на которые не получены разрешения.
Существенно повышает эффективность контроля наличие регистрационного
идентификатора пользователя (LUID). После прохождения пользователем процедур
идентификации и аутентификации, т. е. непосредственного входа в систему,
каждому процессу, создаваемому пользователем, присваивается регистрационный идентификатор
пользователя. Данный идентификатор сохраняется на весь сеанс работы. Каждая
контрольная запись, генерируемая системой контроля, содержит для каждого
процесса регистрационный идентификатор наряду с эффективным и реальным
идентификаторами пользователя и группы. Таким образом, оказывается возможным
учет действий пользователя.
Отдельно следует рассмотреть реализацию механизма контроля для ядра.
Данный механизм генерирует контрольные записи, исходя из деятельности
пользовательских процессов, с помощью системных вызовов ядра. Каждый системный
вызов ядра содержит строку в таблице, где указывается его связь с вопросами
защиты информации и какому типу события он соответствует. Кроме того,
используется таблица кодов ошибок, позволяющая классифицировать системные
вызовы на конкретные события, связанные с защитой информации.